Scraping the Texas death row list
This is a quick exercise in naively using HTML and CSS selectors to extract data. It shows a few more of the pup tool's features, as well as how to interpret a complex document using the natural limitations of the command line, regardless of your expertise in HTML.
However, don't take it as the way to do this kind of data work. It's not even close to the ideal solution. However, going through this exercise will introduce you to a few more HTML-parsing features, the overall difficulty in using just the command-line to handle data, and the many, many imperfections in real world datasets.
This exercise assumes you have pup installed.
Have questions, answer them
Rather than demonstrate all the facets of HTML and HTML parsing, let's have a goal in mind for this tutorial: We want to write a program that scrapes the Texas Department of Criminal Justice's online list of Offenders on Death Row and calculates 3 facts:
- The racial breakdown of the death row inmates
- The oldest death row inmate
- The inmate who entered death row at the oldest age
All of these facts are derivable from the page as is, but takes some manual work to calculate. The exercise here is small scale, with a number of rows in the hundreds. But besides some basic HTML practice, I hope you see how using programming to interpret data that's out in the open can still be an interesting pursuit (especially when we get into visualization).
In this case, though, we'll get blocked early, because the data is not as neat as we assume. In this case, it's just a few typos. In other situations, data errors will be a result of how a system or institution operates, i.e. what it considers to be useful or adequate data.
And, in particular to the current scenario, you should be wondering: is this the kind of data that even needs an automated routine for, given what it contains and the nature and frequency in which it updates? In this case, the answer's pretty obvious, but this is a question that you should always ask, and that is something that involves actual research and insight into the domain.
Scouting the site
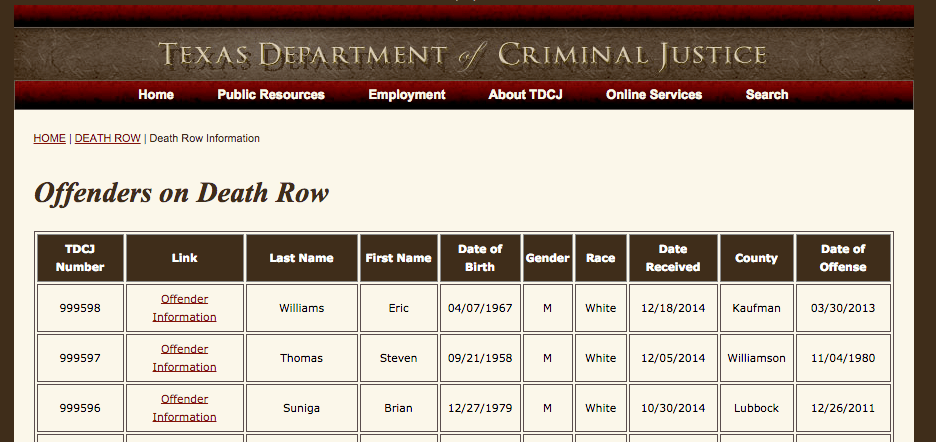
In your browser, open up the Texas Department of Criminal Justice's list of Offenders on Death Row: http://www.tdcj.state.tx.us/death_row/dr_offenders_on_dr.html
Even before viewing the source, you notice a few obvious things. There's a table, for starters, so there's an obvious pattern in the code somewhere. The list is sorted by newest inmate ("Date Received"). Let's take note of the latest date, 12/18/2014, as being the first item in the list.
At this point, you may be tempted to right-click-View-Source, but let's move right to the command-line and see how quickly we can deduce the HTML structure with just our primitive Unix shell and what little we noticed in glancing at the web page.
Download the file
For the rest of this tutorial, let's stash that live URL into a HTML file locally:
curl -s http://www.tdcj.state.tx.us/death_row/dr_offenders_on_dr.html\
> txdr.html
We've done this routinely for earlier types of web scraping/gathering assignments, but let's take a step back and understand the implications here:
We don't need to download the death row listing from the web, over and over, just to process the text. And it is just text, as far as we are concerned. We are solely concerned about the text strings, and it makes no difference if that text comes directly hot of the Internet or sitting in a HTML file on our local hard drive.
So, in summary, the data we need is here (after the curl):
curl -s http://www.tdcj.state.tx.us/death_row/dr_offenders_on_dr.html\
> txdr.html
# data is downloaded
cat txdr.html
Going from small to big
If you're new to HTML, the forest of tags, elements, and syntax of a modern webpage can be absolutely bewildering. So let's start with what we can see – the text displayed by the browser – and use that as the key to find the HTML pattern that we ultimately need.
Find the Date Received column
Do a grep for a specific Date Received: I chose the latest one", 12/18/2014.
user@host:~$ grep '12/18/2014' txdr.html
<td>12/18/2014</td>
OK, so we know these dates are within the <td> tags, so let's use pup to select the <td> elements:
user@host:~$ cat txdr.html | pup 'td'
<td>
999598
</td>
<td>
<a href="dr_info/williamseric.html">
Offender Information
</a>
</td>
<td>
Williams
</td>
<td>
Eric
</td>
Whoa, that's more than we need. Obviously, the <td> element is used to enclose more than just the Date Received columns. Let's go back to grep and use the -B and -A options, which let us specify number of lines to show, respectively, before and after a match is found:
user@host:~$ grep -B 10 -A 7 '12/18/2014' txdr.html
<th scope="col" abbr="date/offense">Date of Offense</th>
</tr>
<tr>
<td>999598</td>
<td>999598</td>
<td><a href="dr_info/williamseric.html">Offender Information</a></td>
<td>Williams</td>
<td>Eric</td>
<td>04/07/1967</td>
<td>M</td>
<td>White</td>
<td>12/18/2014</td>
<td>Kaufman</td>
<td>03/30/2013</td>
</tr>
<tr>
<td>999597</td>
<td><a href="dr_info/thomassteven.html">Offender Information</a></td>
<td>Thomas</td>
A little knowledge of HTML would help here, but we can see some structure here. The <td> tag we want, and several others, are nested inside a <tr> element. That's helpful, but it seems that just like there are many <td> elements, there's probably more than one <tr> element: it looks like there's at least one per <tr> for every row in the table (and in fact, there are, tr is short for "table row").
The insufficiency of line-by-line text processing
At this point, you might think: Well, I know I'm looking for the first inmate, so why don't we use pup to get all the tr elements, then head to select just the first one?
Not a bad idea, conceptually:
user@host:~$ cat txdr.html | pup 'tr' | head -n 1
<tr>
Doh. The plan would've worked if the entire <tr> element was on one line. And sometimes they are. But with <tr> spread across multiple lines, we're in for some complicated grepping and loops (note: things could be easier if you used the awk program, but then you'd have to learn awk, which I'm not going to expect from you).
The power of parsers
Even though HTML is just text, the structure and logic of HTML is too complicated and irregular for standard line-processing tools like grep. But that's why we have pup and other HTML parsers. Their job is to know the twisted logic of HTML and to give us a simplified output to work with.
Referring back to the documentation for pup, we see there are a few selectors that will come in handy. There's one called :nth-of-type(n), which should let us specify something like, "the 3rd element of type <td>".
Using nth-of-type(n) selector
Let's try it: and choose the 1st <tr> element. We'll use grep to match the date we wanted: 12/18/2014
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(1)' | grep '12/18/2014'
# no result
If you run that command again to see the whole output, you'll see that the first row corresponds to the table column headers.
So let's move on to row 2:
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(2)' | grep '12/18/2014'
12/18/2014
Bingo. You can remove the grep call to see the entire <tr> element and where 12/18/2014 is nested:
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(2)'
The output looks like this:
<tr>
<td>
999598
</td>
<td>
<a href="dr_info/williamseric.html">
Offender Information
</a>
</td>
<td>
Williams
</td>
<td>
Eric
</td>
<td>
04/07/1967
</td>
<td>
M
</td>
<td>
White
</td>
<td>
12/18/2014
</td>
<td>
Kaufman
</td>
<td>
03/30/2013
</td>
</tr>
Narrowing down the column rows
So, assuming we can use that nth-of-type(n) selector on each <td> to get what we want, we just have to figure out which <td>, sequentially, contains 12/18/2014.
You can count the <td> elements by hand. Or play around with the command-line to help you. Reading from the bottom, we see that 12/18/2014 is the third <td> from the bottom:
<td>
12/18/2014
</td>
<td>
Kaufman
</td>
<td>
03/30/2013
</td>
</tr>
Using grep to count number of <td> in the selection:
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(2)' | grep -c '<td>'
10
That means 12/18/2014, i.e. the Date Received column, is column 8 (3 up from the 10th column, including that column) Let's add it to the pup selector:
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(2) td:nth-of-type(8)'
<td>
12/18/2014
</td>
Bingo. Let's use pup's text selector syntax to get just the text:
user@host:~$ cat txdr.html | pup 'tr:nth-of-type(2) td:nth-of-type(8) text{}'
12/18/2014
Get all the 8th-columns
Now, let's make pup less specific in its selector. We don't care about rows anymore, we just want the 8th cell of each row:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(8) text{}'
12/18/2014
12/05/2014
10/30/2014
08/01/2014
07/24/2014
05/19/2014
# and so forth ...
10/10/1978
09/12/1978
10/26/1977
02/04/1976
The output looks good. Let's do a quick count of inmates, since we haven't even done that yet:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(8) text{}' | wc -l
275
275 inmates.
This may have seemed like a very long way to counting something basic (and for this tutorial, we don't need to use Date Received)…but besides being good practice with HTML parsing techniques, it let us figure out characteristics of the data after just a brief initial look at the webpage in the browser. The rest was pure command-line technique and reasoning.
Moving on, we now have a way to select all the values of any column in the table, which is basically what we need to answer the questions at the beginning of this tutorial.
Answering the questions
Let's move on to the questions to be answered, with the knowledge that the following selector can be modified to get the text of any column, from every row:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(8) text{}'
The racial breakdown of the death row inmates
This is no different than the previous work we've done in counting words, except the first step involves just extracting the words from the 7th column.
user@host:~$ cat txdr.html | pup 'td:nth-of-type(7) text{}' | \
> sort | uniq -c | sort
4 Other
77 Hispanic
80 White
114 Black
The oldest death row inmate
Let's first try to select all birth dates. The Date of Birth is in the 5th column:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(5) text{}'
04/07/1967
09/21/1958
12/27/1979
07/05/1991
05/30/1979
# ...
11/20/79
08/03/1968
03/26/1980
09/29/1968
05/06/1980
1124/1976
10/01/1980
# ...
Now, theoretically, we should be able to get the oldest inmate by sorting by this field. Unfortunately, there are at least three problems:
- The date is in MM/DD/YYYY format, which will not sort in chronological order, as the default sort goes from left-character to rightmost-character. And in MM/DD/YYYY format, the
YYYYcharacters are the most significant. - To compound the year-positional problem, at least one of the dates is in
MM/DD/YYformat:11/20/79 - Even worse, at least one of the dates has a blatant typo:
1124/1976, which presumably should be,11/24/1976
Data janitorial work
The data errors here are pretty simple, since we're only dealing with a few hundred rows. But in thousand/million-row datasets, dirty data is a major, major problem in most data science work.
Via the New York Times:
Yet far too much handcrafted work — what data scientists call “data wrangling,” “data munging” and “data janitor work” — is still required. Data scientists, according to interviews and expert estimates, spend from 50 percent to 80 percent of their time mired in this more mundane labor of collecting and preparing unruly digital data, before it can be explored for useful nuggets.
It's unglamorous work, but being able to do it efficiently can make the difference between someone who does great data analysis and visualization, and someone who can't do anything with data at all (or has to pay someone a lot of money to clean up the data).
Covering the methods of data munging is far outside the scope of this guide, but in general, if you can treat the data as text, because that's what it is, the text processing tools you know about will get you very far.
(For extremely bad and/or large datasets, you probably want to move beyond Bash and into something like Python or R).
Figuring out the scope of the problem
Let's use the command-line to filter for the erroneous dates. It's pretty easy to figure out the pattern that is correct. So we use regular expressions and grep's -v option to select just the non-matches, i.e. the incorrect patterns:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(5) text{}' | \
> grep -vE '\b[0-9]{2}/[0-9]{2}/[0-9]{4}\b'
7/18/1968
11/20/79
1124/1976
11/6/1971
OK, only four erroneous values. At this point, common sense should prevail, and instead of coming up with a programmatic way to fix this awry data, let's just use the 271 other data points, because it seems pretty obvious that the four erroneous dates aren't among the oldest birthdates.
Cut and sort
To find the oldest inmate in the simplest fashion, we can just sort the fields by using the forward-slash as the delimiter, and sorting by the 3rd field:
user@host:~$ cat txdr.html | pup 'td:nth-of-type(5) text{}' | \
> grep -E '\b[0-9]{2}/[0-9]{2}/[0-9]{4}\b' | \
> sort -t '/' -k 3 | head -n 3
12/23/1937
03/30/1940
07/02/1946
OK, looks like we have a clear winner: 12/23/1937
Inelegant web parsing
The set of commands and filters above only produces the oldest birthdate. If we want to actually get the rest of the information (from the command-line), we can either learn more text-processing tools and syntax, or do something very inelegant with what we know.
I like the latter option, as it fits with Unix creator Ken Thompson's advice, "When in doubt, use brute force"
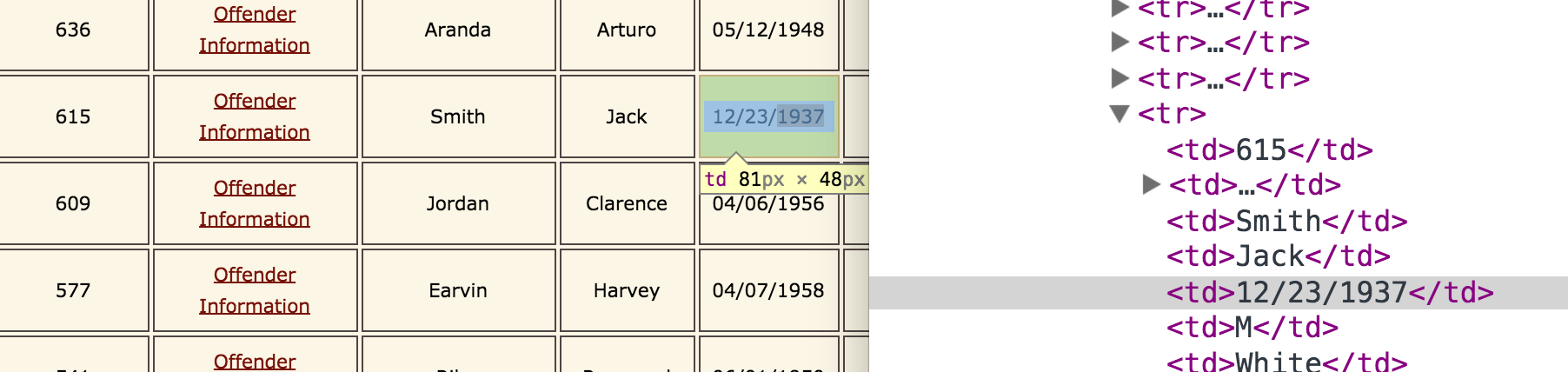
We can't just grep for 12/23/1937, because basic grep only matches across single lines of text. And though each row on the Texas death penalty website looks like a "single line", the underlying HTML is spread across multiple lines:
However, we do know, with pup how to select a single <tr> element, by its position among the order rows. And we know how to convert newlines into space characters. And we know how to loop through a collection of elements.
Here's the quick-and-ugly solution:
# Get the total number of rows
user@host:~$ row_count=$(cat txdr.html | grep -c '<tr>')
# for each row...
user@host:~$ for r in $(seq 1 $row_count)
do
cat txdr.html | pup "tr:nth-of-type($r)" | \
tr -d "\n" | grep '12/23/1937'
done
The output:
<tr> <td> 615 </td> <td> <a href="dr_info/smithjack.jpg" title="Offender Information"> Offender Information </a> </td> <td> Smith </td> <td> Jack </td> <td> 12/23/1937 </td> <td> M </td> <td> White </td> <td> 10/10/1978 </td> <td> Harris </td> <td> 01/06/1978 </td></tr>
The previous snippet of code is wrong in so many ways, but since we've already punted on the question of cleaning up every date in this dataset, there's no point in over-thinking a graceful solution when brute force will do. This solution is more naive than I'd like. On the other hand, it's not too naive. For example, we know that if 12/23/1937 corresponds to the oldest inmate, and that there's only one inmate with that birthdate, then 12/23/1937 will match exactly once (none of the other date fields could legitimately have that same date string, think about it).
This solution doesn't scale for any other dataset, though. But the reality is, fine-toothed data parsing systems should generally not be implemented in Bash.
The inmate who entered death row at the oldest age
Note: To reiterate what I said earlier, and what I repeat below, this is not an example of a best practice. In fact, it's probably one of the most naive and inefficient solutions possible. Even with the few tools/syntax I use, it could be cleaner. But I phoned it in, so don't worry if it seems completely convoluted.
The inmate who entered death row at the oldest age is not the same as the oldest inmate. In the context of the available data, it's the inmate who has the largest gap between their birthdate and the date they entered death row. Basically, we have to get a reverse-sorted list of the differences between column 8 and column 5.
Since we already went the route of a brute-force for-loop, might as well continue the trend. And rather than explore Bash's date utility (since the dates are pretty mangled), let's just subtract year columns.
Believe it or not, everything below is either directly from the code we've used earlier in this lesson, or follows directly from other basic examples we've done…and that's why it looks so ugly. Such is the downfall of sticking to limited tools.
# Get the total number of rows
user@host:~$ row_count=$(cat txdr.html | grep -c '<tr>')
# for each row...
user@host:~$ for r in $(seq 1 $row_count)
do
# Because pup won't parse partial HTML snippets...we extract birthdate
# and received date, and we select the year field. I put a
# grep to filter out bad-year dates, but was clearly too lazy
# to apply a conditional
bdate=$(cat txdr.html | pup "tr:nth-of-type($r) td:nth-of-type(5) text{}" | \
cut -d '/' -f 3 | grep -oE '[0-9]{4}')
rdate=$(cat txdr.html | pup "tr:nth-of-type($r) td:nth-of-type(8) text{}" | \
cut -d '/' -f 3 | grep -oE '[0-9]{4}')
# just get the row of text
row=$(cat txdr.html | pup "tr:nth-of-type($r)" | tr -d '\n')
echo "$((rdate - bdate)), $row"
done | sort -n | grep -E '^[0-9]{1,2},' | tail -n 1
The answer (note that the two out-of-bounds values belong to the two rows with malformed birthdates) of oldest person to enter Texas's death row: Donald Bess at 62 years of age:
62, <tr> <td> 999559 </td> <td> <a href="dr_info/bessdonald.html" title="Offender Information"> Offender Information </a> </td> <td> Bess </td> <td> Donald </td> <td> 09/01/1948 </td> <td> M </td> <td> White </td> <td> 09/27/2010 </td> <td> Dallas </td> <td> 10/13/1984 </td></tr>
Given that the above loop, besides having no error checking, is so inefficient that it takes 38 seconds to execute…it doesn't really count as a good example of good brute force computation.
A tool such as Awk would help to ease the pain. Or better usage of streams, beyond the simple naive examples I've done above. But the bigger picture is: when things get painfully difficult, start thinking about different tools (such as Python and Beautiful Soup)
But the even bigger picture here is that the data needs manual correction, because it seems to be manually entered in. And so an attempt to make a script that automatically calculates such numbers from the live webpage is more work than is worth doing. The better solution would be to make a copy of the data yourself, extract it, clean it, and create your own datastore. And then the question of, "Well how do you keep it in sync?"…