The Celebrity (Tw)It List
Using the t command-line Twitter tool, find the most popular Twitter users, and then find who they follow. The result is, purportedly, an elite list of Twitter users who have the most influence over “celebrities”. This is a (hopefully) fun exercise in traversing networks with data, as we try to compile data by following links from one datapoint to the next.
Deliverables
A project directory named twitter-celeb-list
The project folder will look like this:
|-- compciv/
|-- homework/
|-- twitter-celeb-list/
|-- t-bouncer.sh (get info on "celebrities" from Twitter API)
|-- t-lister.sh (generate list of highly-followed users)
|-- top-100.csv (the list of 100-most followed users and who follows them)
|-- data-hold/
|-- followings/ (cache the followings list of users)
t-bouncer.sh
The t-bouncer.sh script should take in, as an argument, a CSV or list of CSV files of Twitter users, as produced by the t program. It then filters this listing of users like so:
-
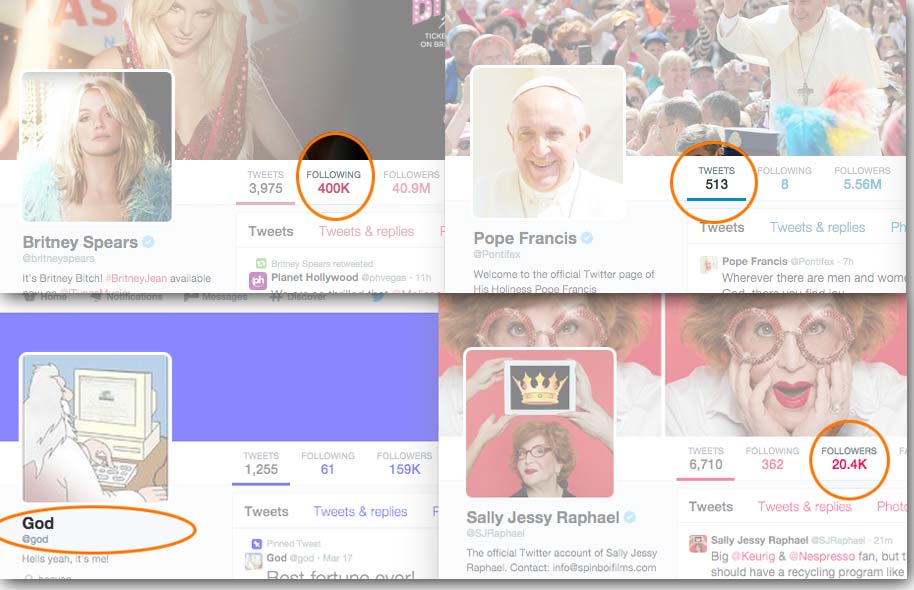
Filter the list for users for “celebrities” who actually use Twitter. This is how I’m defining such a “celebrity”:
- Is verified - this is some assurance that this person has a brand/identity important enough for Twitter to vouch for.
- Has more than 50,000 followers - Another small assurance of real-world popularity
- Is following 1,000 or fewer users - this is to ignore accounts that are probably just used for PR/brand-management purposes, rather than the person tweeting themselves.
- Has created at least 1,000 tweets - if they aren’t tweeting much, then maybe they haven’t bothered to nitpick over their own followings-list.
In other words, the following users will be filtered out as not being “celebrities” (at least, in the personal-Twitter-sense):
- @britneyspears - follows too many users
- @Pontifex - hasn’t tweeted enough
- @God - is not Verified
- @SJRaphael - not enough followers
-
For the users who are allowed through the filter, i.e. the “celebrities”,
t-bouncer.shwill then collect a list of whom they follow, and save it to a file:data-hold/followings/the_username_in_lowercase.csv
In other words, data-hold/followings/ will contain files, each one named after a “celebrity’s” Twitter username. And within each of those files contains the list of people whom the “celebrity” follows.
t-lister.sh
The t-lister.sh script expects data-hold/followings to contain a bunch of CSV files containing lists of followed Twitter users. It reads through all of these CSV files and counts up the usernames found in all the files (i.e. using a combination of sort and uniq -c)
It then filters that list of username counts to include only usernames that appear 5 or more times (i.e. followed by at least 5 different celebrity users).
And then, it outputs a list that looks like this:
thedude,walter
thedude,donny
thedude,bunny
thedude,brandt
jefflebowski,bunny
jefflebowski,brandt
jefflebowski,woo
Each line in that output is a comma-delimited data row of two columns: the username of a followed Twitter user, and the user who follows that user. In the above example, thedude is followed by walter, donny, bunny, and brandt
The reason to include multiple rows per followed user is because it’s interesting to see who the followers are. And also, because it’s dead simple to get just the list of unique followed users:
bash t-lister.sh | cut -d ',' -f 1 | sort | uniq
top-100.csv
Create this file with the output produced by t-lister.sh. It will contain far more than 100 rows, but doing this:
cat top-100.csv | cut -d ',' -f 1 | sort | uniq | wc -l
– should result in 100
Be aware that the names in this list do not themselves have to fit our definition of “celebrity”. For example, your top-100.csv will most likely contain user barackobama.
Hints
Example usage
This assignment's description is a little verbose and it may be hard to create a mental picture of the effect of t-bouncer.sh. So, first, try to read the entirety of the Hints section. And if you're confused, then here's a more visual depiction of how things should work:
Getting a "seed"
Let's say you're a big Jonah Hill fan. You do a Google search for his Twitter account, which is at @JonahHill, and you notice that he fits our definition of a Twitter celebrity (verified, 50,000+ followers, less than 1,000 users followed, more than 1,000 tweets made).
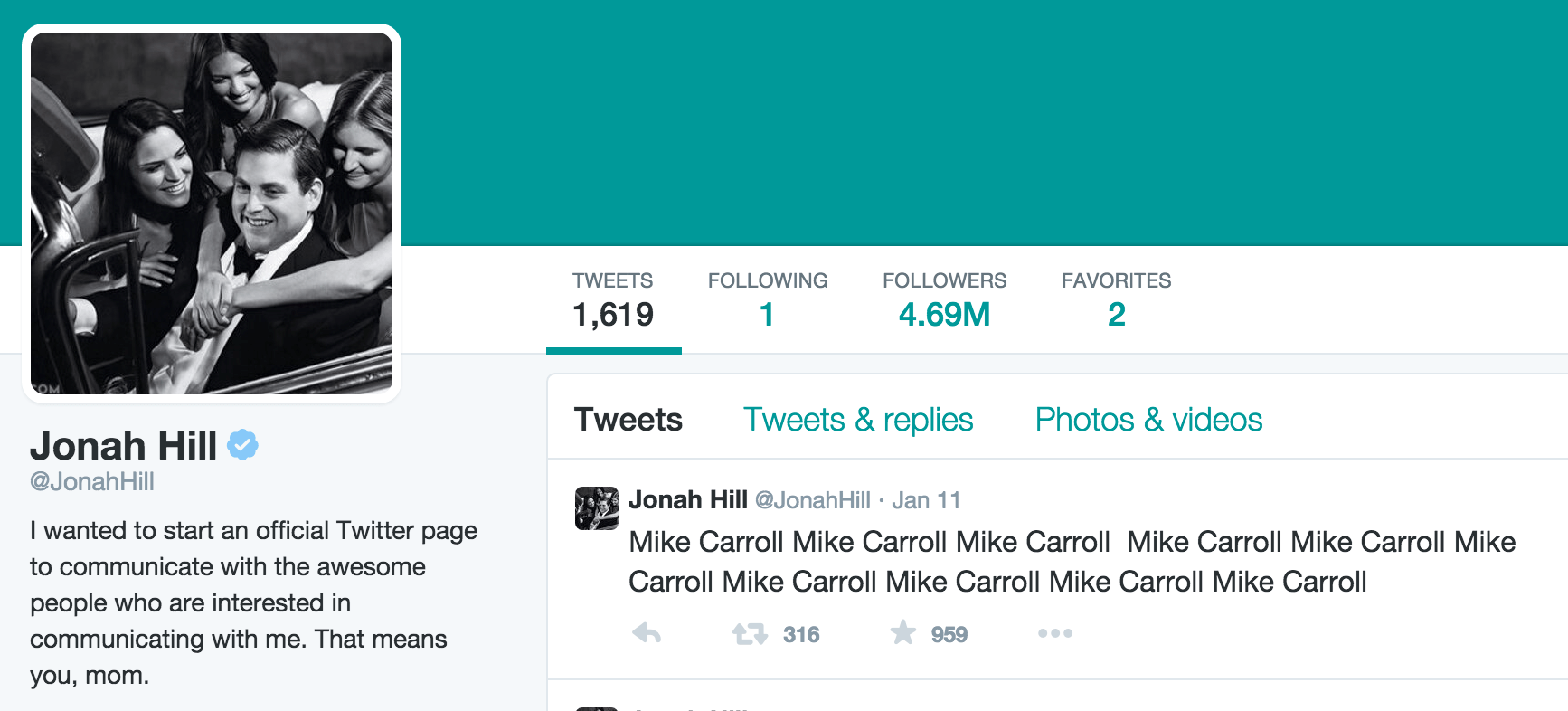
So you manually download his followings list into your currently empty data-hold/followings/ folder. You can think jonahhill.csv as being the seed:
t followings jonahhill > data-hold/followings/jonahhill.csv
OK, now data-hold/followings/ contains a single file:
data-hold/followings/jonahhill.csv
First run of t-bouncer.sh
Now, if you've designed t-bouncer.sh properly, you can execute it like this:
bash t-bouncer.sh data-hold/followings/*.csv
As it turns out, @JonahHill, at the time of writing, follows exactly one user: @BlondieOfficial.
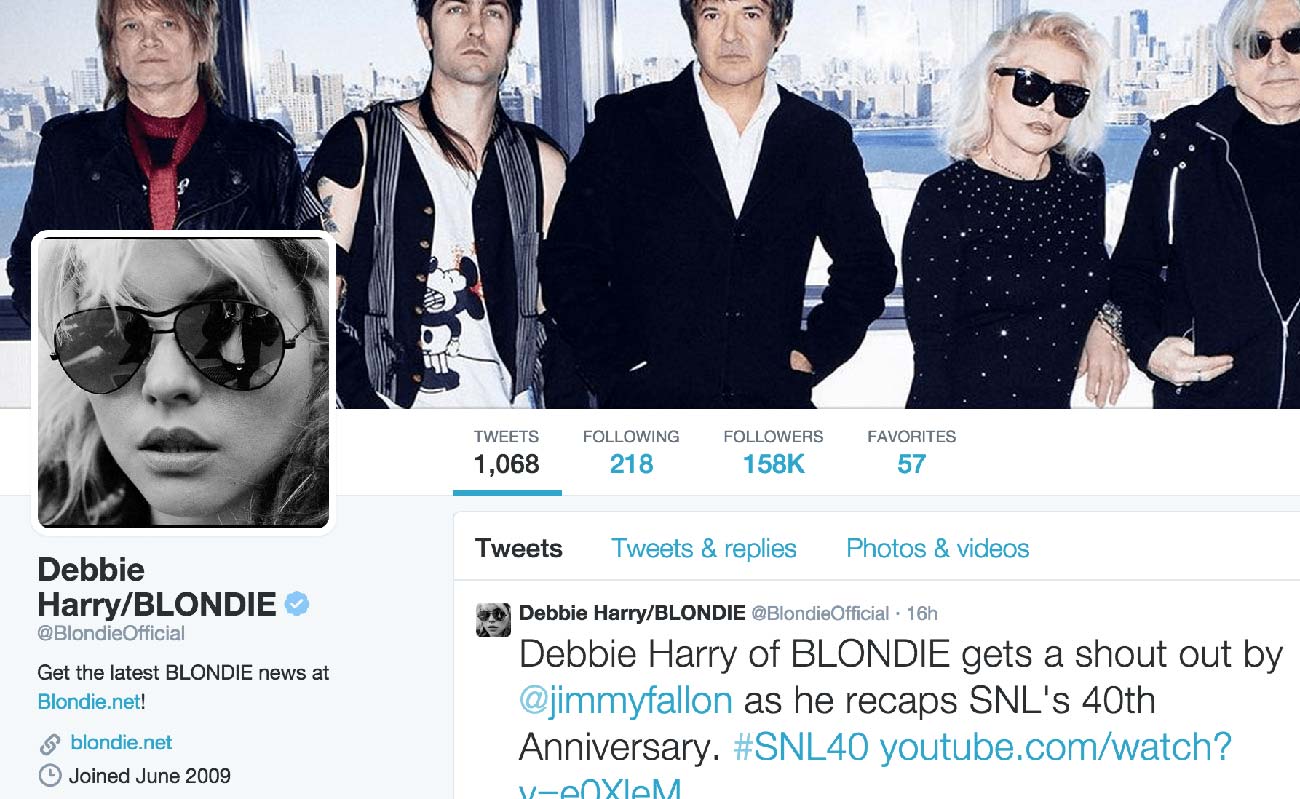
Now, if @BlondieOfficial didn't meet our definition of a "celebrity", the t-bouncer.sh script would do nothing – because it begins by first filtering each CSV file for "celebrities".
However, it just so happens that @BlondieOfficial meets our definition of a Twitter "celebrity", and so t-bouncer.sh will fetch her list of followings and save it into data-hold/followings/blondieofficial.csv.
So now data-hold/followings contains:
- jonahhill.csv
- blondieofficial.csv
Second run of t-bouncer.sh
You can run t-bouncer.sh the same way as the first:
bash t-bouncer.sh data-hold/followings/*.csv
Because you've told t-bouncer.sh to go through every CSV in data-hold/followings, it will again filter jonahhill.csv and see that it contains a "celebrity" listing, @BlondieOfficial.
But if you've designed t-bouncer.sh to not fetch already-fetched files, i.e. data-hold/followings/blondieofficial.csv, then it should skip fetching that, and then move on to filtering data-hold/followings/blondieofficial.csv for celebrities.
As of time of writing, @BlondieOfficial follows 218 users, 80 of whom are celebrities. So t-bouncer.sh will end up downloading 79 new CSV files (as it turns out @BlondieOfficial also follows @JonahHill, and we already have data-hold/followers/jonahhill.csv)
So here's what your data-hold/followers/ directory will look like after each step:
| Seed | 1st run | 2nd run |
|---|---|---|
| jonahhill.csv |
jonahhill.csv
blondieofficial.csv |
jonahhill.csv
blondieofficial.csv aaronpaul_8.csv abcnetwork.csv actuallynph.csv aliciakeys.csv beatsmusic.csv bettemidler.csv bloomingdales.csv cher.csv chrislilley.csv coachella.csv conanobrien.csv cyndilauper.csv davejmatthews.csv ditavonteese.csv dixiechicks.csv ellenpage.csv fabnewyork.csv genesimmons.csv goldiehawn.csv gothamist.csv gracehelbig.csv grantland33.csv greatdismal.csv guardianmusic.csv haimtheband.csv harpersbazaarus.csv hitrecord.csv howardstern.csv huffpostgay.csv i_d.csv iamrashidajones.csv itunesmusic.csv janemarielynch.csv jimmybuffett.csv jimmykimmel.csv johnstamos.csv jpgaultier.csv jtimberlake.csv karllagerfeld.csv katyperry.csv kevinspacey.csv kimletgordon.csv lenadunham.csv lilyallen.csv lordemusic.csv louisvuitton.csv louisvuitton_uk.csv mileycyrus.csv mrssosbourne.csv newyorker.csv nylonmag.csv nymag.csv nytimes.csv officialrodarte.csv oprah.csv ournameisfun.csv paulmccartney.csv pearljam.csv pink.csv rollingstone.csv russellcrowe.csv ryanseacrest.csv spinmagazine.csv stevemartintogo.csv susansarandon.csv thewho.csv time.csv u2.csv unrightswire.csv vanityfair.csv vicenews.csv vmagazine.csv voguemagazine.csv wmag.csv worldmcqueen.csv wsj.csv wwd.csv youtube.csv zooeydeschanel.csv |
As you can see, the contents of data-hold/followings/ are likely to grow exponentially, which makes sense, if we assume that interesting/elitist people will themselves follow interesting/elitist people.
However, in the above example, you'll need to run t-bouncer.sh a third time, as you need a minimum of 100 CSV files (i.e. the followings of 100 "celebrities") in data-hold/followings/.
Hints
Using iconv
This is important.
I highly suggest using csvfix for parsing the CSV files. That said, csvfix has a near-fatal flaw: it doesn't like UTF-8 encoded files. If you really care about the byte-level details of what UTF-8 is, and how it makes programmers' lives a frequent hell, check out Joel Spolsky's article, The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
For our purposes, it means that things like emoticons-as-text can cause errors:
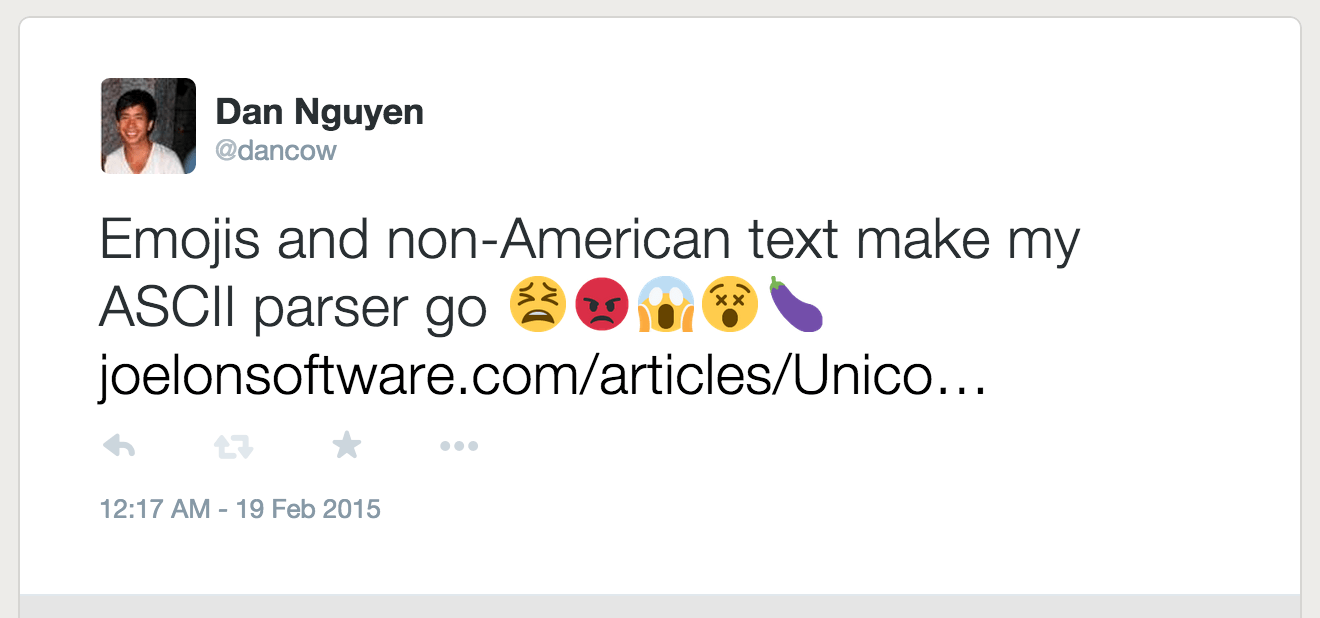
The easy-fix is to use the iconv program to delete all non-ASCII (i.e. simple American-English) characters, which is fine for our purposes because Twitter screen names can only contain ASCII characters anyway. Here's an example usage:
t followings --csv stanford |
iconv -c -f utf-8 -t ascii > data-hold/followings/stanford.csv
Where do I get a list of celebrities
What might be slightly confusing is: well, where do we get a list of "celebrities" to begin with?
The answer: From any list of users that the t program generates.
For example, you could start with the list of users followed by @Stanford:
t followings --csv stanford |
iconv -c -f utf-8 -t ascii > data-hold/followings/stanford.csv
I've saved a cached list of this CSV here, which you can curl at your convenience. At the time of my writing this, @Stanford follows 931 users, and at least a few of them meet my requirements for being a "celebrity".
We can use csvfix to quickly filter this list (see its documentation for all of its commands here). For example, to find all verified users (i.e., users which have true for the Verified column) with more than 50,000 followers:
cat data-hold/followings/stanford.csv |
csvfix find -f 11 -s 'true' |
csvfix find -if '$8 > 50000'
I'll let you write the rest of the filters needed (making more calls to csvfix find should be sufficient) to meet my stated requirements for a "celebrity": verified, more than 50,000 followers, fewer than 1,000 followed users, and more than 1,000 tweets. If you run your filtering command on the sample list here, you should get a list of 50 users, including AmbassadorRice, Atul_Gawande, BillGates, CarlyFiorina.
Your t-bouncer.sh script should run like this:
bash t-bouncer.sh data-hold/followings/stanford.csv
And for every "celebrity" Twitter user in that CSV, the t-bouncer.sh uses t to download and save a new list of followings. So if the stanford followings CSV contains 50 eligible "celebrities", t-bouncer.sh should have created 50 new CSV files in data-hold/followings/
How do I get enough usernames to fill out top-100.csv?
So no matter if data-hold/followings/ contains one CSV or 1,000 CSV, t-lister.sh should do its job of collating/counting up the "cool" users. However, depending on how many followings-lists you've collected, t-lister.sh may not return enough followed-users…remember, the criteria for inclusion on top-100.csv is that a user is followed by at least three different users…in other words, an eligible user name exists in at least three or more CSVs inside data-hold/followings/.
So at a minimum, you need to have collected the followings-list for at least 100 "celebrities". If all of these celebrities have 5-or-more followed-users in common, then your t-lister.sh script will have enough unique user names to fill out top-100.csv
Remember that top-100.csv may contain hundreds/thousands of rows, since it contains the pairs of usernames and the celebrities who follow them. But running:
cat top-100.csv | cut -d ',' -f 1 | sort | uniq | wc -l
– should yield a result of 100
How do get more and more lists of "celebrities"?
Let's say the @Stanford list of followed users doesn't generate enough users for top-100.csv, where do you go to next for more eligible celebrities?
Well, why not gather new celebrities from the list of users contained within all the CSVs in data-hold/followings/? After all, the users that @Stanford follows must themselves follow a few eligible "celebrities".
So basically, you can keep doing this:
bash t-lister.sh | cut -d ',' -f 1 | sort | uniq | wc -l
# is the output 100? If not, then:
bash t-bouncer.sh data-hold/followings/*.csv
bash t-lister.sh | cut -d ',' -f 1 | sort | uniq | wc -l
# is the output 100? If not, then:
bash t-bouncer.sh data-hold/followings/*.csv
bash t-lister.sh | cut -d ',' -f 1 | sort | uniq | wc -l
# is the output 100. If so, then:
bash t-lister.sh > top-100.csv
git add --all
git commit -m "I'm all done"
git push
If you really can't be bothered to keep repeating that sequence of commands…remember the while construct?
user_count=0
while [[ $user_count < 100 ]]; do
echo "Elite user count at $user_count"
bash t-bouncer.sh data-hold/followings/*.csv
user_count=$(bash t-lister.sh | cut -d ',' -f 1 | sort | uniq | wc -l)
done
Warning: if you start out with a bad "seed", i.e. subsequent runs of t-bouncer.sh don't produce any new "celebrities", from which you can continue to branch out…then this while loop will run forever. You can prevent that by creating another condition; for example, the following code uses another variable to count the total number of times that the loop has executed, quitting after 10 times (remember that it's possible for t-bouncer.sh to retrieve data for an exponentially-increasing number of users with each execution):
loop_count=0
user_count=0
while [[ $user_count < 100 && loop_count < 10 ]]; do
echo "Elite user count at $user_count (Loop has run $loop_count times)"
bash t-bouncer.sh data-hold/followings/*.csv
user_count=$(bash t-lister.sh | cut -d ',' -f 1 | sort | uniq | wc -l)
loop_count=$((loop_count+1))
done
Watch out for rate-limits
Remember that Twitter's API has a rate limit. For our purposes, this means that you can't get the list of followers for no more than 15 "celebrities" per 15 minutes.
So t-bouncer.sh must include at least two features:
- Inside
t-bouncer.sh, you'll likely have some kind of loop, because for each eligible username, you'll be callingt followings. So in that loop, you should be running the sleep command to sleep for at least 60 seconds. - You should not be re-collecting data for users for which you already have CSV files for in
data-hold/followings/. In other words, you need an if-statement.
So your t-bouncer.sh script should contain logic that looks like this:
# assume that this part of the code is within a loop in which $username
# contains a Twitter username to possibly fetch the followings-data for
lowercase_name=$(echo $username | tr '[:upper:]' '[:lower:]')
filename="data-hold/followings/$lowercase_name.csv"
if [[ -s "$filename" ]]; then
echo "Already have followings-list for $lowercase_name"
else
echo "Getting followings for $lowercase_name"
# run your code to execute the appropriate t program and save the data
# ...
sleep 60
echo "Now sleeping for 60 seconds"
fi
# ... and continue with the rest of the t-bouncer.sh scritp
Note: There are other, more efficient and cleverer ways to design this loop. In fact, it's probably better to include a limit of new files to fetch within t-bouncer.sh, because t-bouncer.sh could conceivably run for what will seem like forever.
Here's an alternative, which incorporates an if-statement within an if-statement:
# assume that this part of `t-bouncer.sh` is within a loop in which
# the username variable is filled in
# in addition, assume that users_fetched variable has been set to 0
# at the beginning of the `t-bouncer.sh`
if [[ $users_fetched -lt 15 ]]; then
lowercase_name=$(echo $username | tr '[:upper:]' '[:lower:]')
filename="data-hold/followings/$lowercase_name.csv"
if [[ -s "$filename" ]]; then
echo "Already have followings-list for $lowercase_name"
else
echo "Getting followings for $lowercase_name; $users_fetched users fetched so far" # run your code to execute the appropriate t program and save the data
# ...
# instead of sleeping for 60 seconds, just move on to the
# next username...let whatever calls `t-bouncer.sh` do the
# necessary sleeping
users_fetched=$((users_fetched + 1))
fi
fi
## continue on with the rest of `t-bouncer.sh`
The effect of your starting point
If you decide to start off by pointing t-bouncer.sh to a different list than @Stanford's followings, say, the 137 users followed by @SarahPalinUSA, the result of your top-100.csv may look very different. In other words, the make-up of top-100.csv, which consists of the output of the arbitrary cut-off – 100 users with 5-or-more-followers among the celebrities you've collected – from t-lister.sh, depends very much on the kind of users who exist on your "celebrities" followed-lists and in which order you collect them.