Touring the Spotify API from the Command Line
Later this week I'll be posting an extra-credit assignment that involves writing a command-line script that auto-generates a playlist of relevant music, based on an artist's name provided by a user.
How can a program determine "relevant" music? It could start in a way similar to the way that a human might: look at the artists relevant to the given artist. Here's the web interface for the artists that Spotify thinks are "related" to Beyoncé:
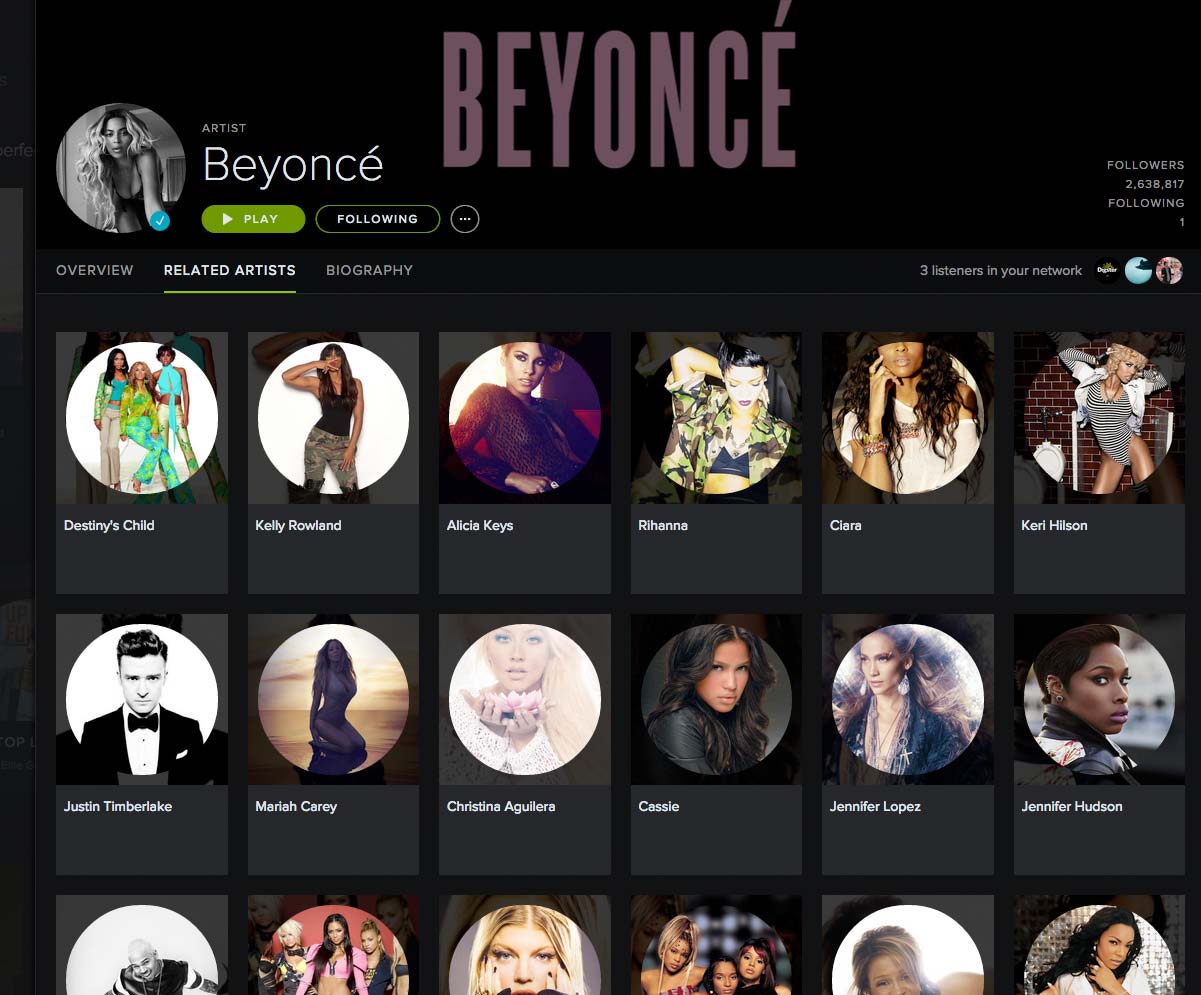
In this tutorial, we'll see what that ("related") means in the actual machine-readable data that Spotify provides.
Why Spotify
There are a few commercial music APIs out there: Spotify, Echo Nest (which has been acquired by Spotify), Last.fm, and Beats Music.
I've chosen Spotify, not as an explicit endorsement of the service, but it's the one I currently use, and I only have time to document one service's API. More importantly, Spotify's API doesn't require an authenticated account to try things out. This guide and the associated assignment takes advantage of these public endpoints. The API is also well-documented and robust, however, as with all commercial APIs, the instructions here could become irrelevant next year or next week – the same with my previous guides on Twitter and Instagram (1, 2)).
But our purpose is to see how real-world information are modeled as textual data – these APIs happen to be convenient sources of interesting information. The principles in parsing and accessing them are applicable to any kind of information.
Tools required
Spotify produces its data as JSON, so we'll be using curl for the downloading of the JSON and jq for the parsing. For producing the simple HTML tables, I use the csvfix printf command.
The public endpoints
You can see all of the Spotify API's endpoints in their guide here. For the purposes of programmatically building a relevant playlist – and because we're using just Bash, which is very much not the ideal language for this – here are the three endpoints that I believe are most relevant:
-
Search for an item - to get the Spotify unique identifier from the human-readable name of an artist, e.g.
6vWDO969PvNqNYHIOW5v0mfor"Beyonce".https://api.spotify.com/v1/search -
Get an Artist’s Related Artists - to get information about 20 artists that are most closely associated to a given artist, based on Spotify users' listening history.
https://api.spotify.com/v1/artists/{ARTIST_ID}/related-artists -
Get an Artist’s Top Tracks - Get the top 10 most popular (based on Spotify's definition of popularity) tracks of an artist for a particular country.
https://api.spotify.com/v1/artists/{ARTIST_ID}/top-tracks?country={COUNTRY}
So one possible algorithm for generating a relevant playlist is: given an artist name, such as "Beyoncé", find the artists most associated with her according to the listening habits of Spotify's userbase, and then build a list of the top tracks of those artists. This is pretty straightforward in theory. But as it turns out, there's a lot of nuance and personal opinion that can be applied to this general algorithm.
For now, we'll just focus on how to access the API and what data it returns.
Search for an item
The endpoint:
https://api.spotify.com/v1/search
The search endpoint can be used to search across song and album titles. We are only interested in finding artists, so we add the type parameter to the endpoint:
https://api.spotify.com/v1/search?type=artist
The other required component of the call is the q (query) parameter, which we specify what we're searching for.
If it's Beyoncé we want (note how I've omitted the capitalization and the accented é in the API call, as it ends up not making a difference), this is the URL for searching for her record in Spotify's artists database:
https://api.spotify.com/v1/search?type=artist&q=beyonce
As with most publicly-facing web-based APIs, you can visit the URL in your browser. If you're using Chrome, you can download the JSONView plugin which will automatically prettify the display of JSON.
In this screenshot of the Spotify response, I've highlighted the important bit: the id field:
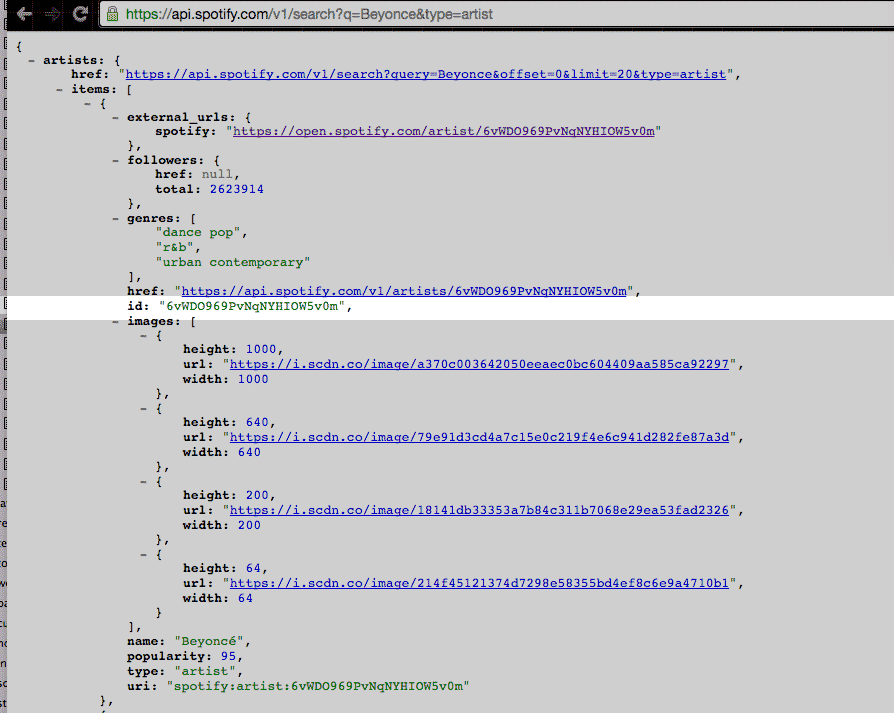
So when referring to Beyoncé as a data object, Spotify uses the id of 6vWDO969PvNqNYHIOW5v0m to keep track of her.
If you search for Spotify's webpage for the artist known as Beyoncé, you'll see this convoluted identifier in use:
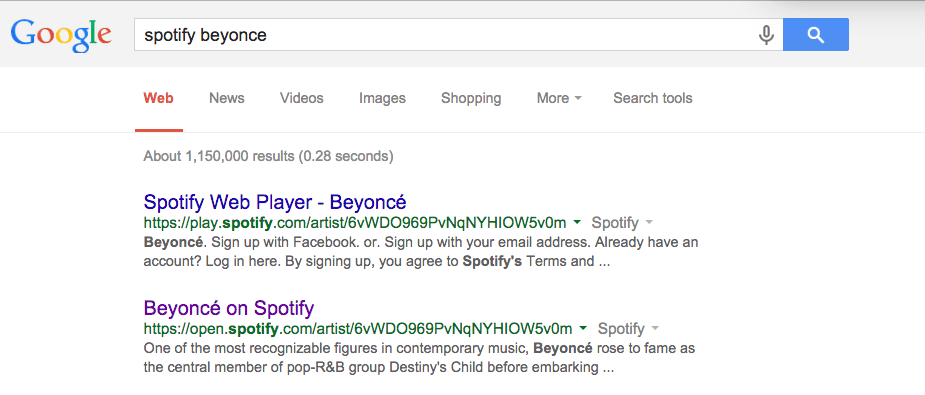
The id is used in the URL for her Spotify web presence:
https://play.spotify.com/artist/6vWDO969PvNqNYHIOW5v0m

Wherefore art thou 6vWDO969PvNqNYHIOW5v0m
For the other endpoints in Spotify's APIs, such as finding related artists, this Spotify unique id is required, which is why we have to use the Search endpoint in the first place.
But it's natural to ask, why can't Spotify know that "Beyonce" means the one and only, Beyoncé? As it turns out, there is more than one Beyoncé out there. Let's use curl and jq to find out who they are:
(if the Spotify API is unavailable, I have a cached response that you can curl here)
# cache the response
curl -s "https://api.spotify.com/v1/search?type=artist&q=beyonce" > /tmp/search-beyonce.json
# count the results returned
cat /tmp/search-beyonce.json | jq '.artists .items | length'
# display the first 10 results, with artist name, popularity, number of followers
cat /tmp/search-beyonce.json |
jq --raw-output \
'.artists .items[] | [.name, .popularity, .followers .total] | @csv' |
head -n 10
The output:
"Beyoncé",95,2637753
"Beyonce & Shakira",30,13663
"Mc Beyonce",37,1723
"Performed by Beyoncé Knowles,;Sharon Leal;Anika Noni Rose;Dreamgirls (Motion Picture Soundtrack)",20,1682
"Performed by Jennifer Hudson;Beyoncé Knowles;Anika Noni Rose;Dreamgirls (Motion Picture Soundtrack)",19,434
"Missy Elliott / Beyonce",25,105
"Beyoncé and Bilal",21,129
"Knowles Beyoncé",7,6
"Performed by Jamie Foxx,;Beyoncé Knowles;Dreamgirls (Motion Picture Soundtrack)",7,161
"Performed by Jamie Foxx,;Jennifer Hudson;Beyoncé Knowles;Keith Robinson;Anika Noni Rose;Dreamgirls (Motion Picture Soundtrack)",12,477
So most of these results (which are apparently returned in order of popularity) are the way that Beyoncé's collaborations with other artists are considered to be each their own musical act, and hence, each deserves their own unique identifier. Wouldn't it make more sense to keep Beyonce and Shakira separate, rather than creating an artist object for the one time they collaborated on "Beautiful Liar - Freemasons Club Remix"? Sure &ndas; let's ignore the technical complications of that – but then what do you do about bands? Instead of having Fleetwood Mac in the artists database, have each band member in the database, so that Stevie Nicks fans can find Fleetwood Mac music limited to when she was in the band. Or to put it another way, is Fleetwood Mac pre-Stevie Nicks the same thing as the Fleetwood Mac after she joined? Not really an easy thing to keep the details straight in a database, so Spotify is probably just going by with the way the music industry has organized records and artists.
The bottom line is: when dealing with any kind of organized database, expect to deal with that database's unique identifiers, not with the general name for an entity.
Get an Artist’s Related Artists
Now that we know Beyoncé's name in Spotify's database, 6vWDO969PvNqNYHIOW5v0m, we can use this to find artists related to her.
The endpoint:
https://api.spotify.com/v1/artists/{ARTIST_ID}/related-artists
The "similarity" between artists is "based on analysis of the Spotify community's listening history". From Spotify's 2010 press release on this feature:
Previously we’ve used genre and artist tagging from AllMusic for related artists which worked well, but did not cover a large portion of our catalogue. What we’ve done now is to go through months and months of listening data and look closely at what people listen to.
This allows us to see that users who listen to a lot of The Rolling Stones, for example, are also big fans of Iggy Pop or The Byrds. The new feature pulls some of this information together to show you a range of related artists in one tab.
In other words, Spotify believes that what their users do – such as putting Rolling Stones, Iggy Pop, and The Byrds on the same playlist – is a good sign that these artists are related. Even if the genres, time periods of popularity, and even musical styles, might be different.
The URL to access the API's data on artists most similar to Beyoncé is this:
https://api.spotify.com/v1/artists/6vWDO969PvNqNYHIOW5v0m/related-artists
# cache the call
curl -s https://api.spotify.com/v1/artists/6vWDO969PvNqNYHIOW5v0m/related-artists > /tmp/related-to-beyonce.json
cat /tmp/related-to-beyonce.json | jq --raw-output \
'.artists[] | [.name, .popularity, .followers .total] | @csv'
The output:
"Destiny's Child",76,276673
"Kelly Rowland",74,311212
"Alicia Keys",83,695402
"Rihanna",92,4887810
"Ciara",77,359301
"Keri Hilson",70,109320
"Justin Timberlake",87,1397414
"Mariah Carey",81,603411
"Christina Aguilera",85,638784
"Cassie",67,54117
"Jennifer Lopez",82,881666
"Jennifer Hudson",70,74698
"Chris Brown",94,2061306
"The Pussycat Dolls",73,176299
"Fergie",81,186367
"TLC",75,158597
"Whitney Houston",78,498428
"Ashanti",71,92272
"Kelis",72,66580
"Mary J. Blige",77,254076
Make some HTML
Just for fun: we can make a data visualization later, but let's make a simple HTML table to show the artists. Review the lesson on programatically making HTML (using herdocs and printf). In the following example, I pipe the output of the parsed JSON to the csvfix tool, specifically, its version of printf.
# Make a template for each table row
# Make a template for each table row
read -r -d '' rowtemplate <<'EOF'
<tr>
<td class="name">
<a href="%s">
<img src="%s">
<strong>%s</strong>
</a>
</td>
<td class="popularity">%s</td>
<td class="followers">%s</td>
</tr>
EOF
# write table styles
cat <<'EOF'
<style>
table.artists{ width: 500px }
table.artists td{ padding: 2px 6px; }
table.artists td.name{ text-align: left; }
table.artists td.name img{ max-height: 80px; margin-right: 10px; }
table.artists td.popularity, table.artists td.followers{
text-align: right;
}
</style>
EOF
## Write table code
cat <<'EOF'
<table class="artists">
<thead>
<tr>
<td>Name</td>
<td>Popularity</td>
<td>Followers</td>
</tr>
</thead>
<tbody>
EOF
cat /tmp/related-to-beyonce.json |
jq -r '.artists[] | [.external_urls .spotify, .images[1] .url, .name, .popularity, .followers .total] | @csv' |
csvfix printf -fmt "$rowtemplate"
# closing tag
echo "</tbody></table>"
The result:
| Name | Popularity | Followers |
 Destiny's Child
Destiny's Child
|
76 | 276673 |
 Kelly Rowland
Kelly Rowland
|
74 | 311212 |
 Alicia Keys
Alicia Keys
|
83 | 695402 |
 Rihanna
Rihanna
|
92 | 4887810 |
 Ciara
Ciara
|
77 | 359301 |
 Keri Hilson
Keri Hilson
|
70 | 109320 |
 Justin Timberlake
Justin Timberlake
|
87 | 1397414 |
 Mariah Carey
Mariah Carey
|
81 | 603411 |
 Christina Aguilera
Christina Aguilera
|
85 | 638784 |
 Cassie
Cassie
|
67 | 54117 |
 Jennifer Lopez
Jennifer Lopez
|
82 | 881666 |
 Jennifer Hudson
Jennifer Hudson
|
70 | 74698 |
 Chris Brown
Chris Brown
|
94 | 2061306 |
 The Pussycat Dolls
The Pussycat Dolls
|
73 | 176299 |
 Fergie
Fergie
|
81 | 186367 |
 TLC
TLC
|
75 | 158597 |
 Whitney Houston
Whitney Houston
|
78 | 498428 |
 Ashanti
Ashanti
|
71 | 92272 |
 Kelis
Kelis
|
72 | 66580 |
 Mary J. Blige
Mary J. Blige
|
77 | 254076 |
It's worth pointing out that the Spotify's Related Artist API doesn't return results by popularity or follower count, but by their similarity score (which is not returned as a number). So when creating an algorithm for playlist generation, you have several options: do you choose the artists at the top of the list, i.e. the artists liked by most Spotify users who also like Beyoncé? Or do you sort the list by popularity, which would put Chris Brown at the top? Or maybe you pick the least popular artist (Cassie) of the given group of related artists, on the basis that these artists might be yet undiscovered by the Beyoncé fan?
Or, you pick the artists related to these artists (producing as many as 400 different artists, if there aren't any duplicates)…?
Get an Artist’s Top Tracks
However you choose the artists to place on a playlist, you'll eventually have to pick which tracks to sample from. For this, we can use the top tracks endpoint:
https://api.spotify.com/v1/artists/{ARTIST_ID}/top-tracks?country={COUNTRY}
The documentation.
So imagine that you (or your algorithm) have decided that your friend (i.e. user) just must listen to Beyoncé – but what of Beyoncé's vast ouevre? Her highest ranking track on the current Billboard charts (7/11, as of February 2015)? Or her #1 singles of all time, such as Crazy in Love or Single Ladies? Or maybe you think her best work were singles not packaged for mainstream consumption, and you agree with The Atlantic's Nolan Feeney that Jealous, from her eponymous album Beyoncé, "is not only one of the best songs on her moody, minimalist album, it’s also one of the most important songs in her catalog."
This is another place where human judgment and preferences can have a major impact on algorithm design. For the purposes of this simplified exercise, we defer to the top 10 tracks as ranked by popularity among Spotify users.
Using Beyoncé (i.e. 6vWDO969PvNqNYHIOW5v0m) as the example, this is the call to get her 10 most popular tracks on Spotify in the U.S. market:
https://api.spotify.com/v1/artists/6vWDO969PvNqNYHIOW5v0m/top-tracks?country=US
curl -s "https://api.spotify.com/v1/artists/6vWDO969PvNqNYHIOW5v0m/top-tracks?country=US" > /tmp/top-10-beyonce.json
cat /tmp/top-10-beyonce.json |
jq --raw-output '.tracks[] | [.name, .album .name, .popularity] | @csv'
The output:
"7/11","BEYONCÉ [Platinum Edition]",92
"Drunk in Love","BEYONCÉ [Platinum Edition]",82
"Flawless Remix","BEYONCÉ [Platinum Edition]",80
"XO","BEYONCÉ [Platinum Edition]",79
"Crazy in Love","Dangerously In Love",78
"Halo","I AM...SASHA FIERCE",78
"Partition","BEYONCÉ [Platinum Edition]",78
"Run the World (Girls)","4",77
"Love On Top","4",77
"Haunted","BEYONCÉ [Platinum Edition]",76
As in the previous example, I'll throw the result into a HTML table using csvfix printf:
read -r -d '' rowtemplate <<'EOF'
<tr>
<td class="album">
<a href="%s">
<img src="%s">
%s
</a>
</td>
<td class="name">
<strong>%s</strong>
<a href="%s" target="_blank">
[Preview]
</a>
</td>
<td class="popularity">%s</td>
</tr>
EOF
# write table styles
cat <<'EOF'
<style>
table.tracks{ width: 700px }
table.tracks td{ padding: 2px 6px; }
table.tracks td.album, table.tracks td.name{ text-align: left; }
table.tracks td.album img{ max-height: 80px; margin-right: 10px; }
table.tracks td.popularity, table.tracks td.duration{
text-align: right;
}
</style>
EOF
## Write table code
cat <<'EOF'
<table class="tracks">
<thead>
<tr>
<td>Album</td>
<td>Track</td>
<td>Popularity</td>
</tr>
</thead>
<tbody>
EOF
cat /tmp/top-10-beyonce.json |
jq -r '.tracks[] | [
.album .external_urls .spotify,
.album .images[1] .url,
.album .name,
.name,
.preview_url, .popularity] | @csv' |
csvfix printf -fmt "$rowtemplate"
# closing tag
echo "</tbody></table>"
The result
| Album | Track | Popularity |
 BEYONCÉ [Platinum Edition]
BEYONCÉ [Platinum Edition]
|
7/11 [Preview] | 92 |
|
BEYONCÉ [Platinum Edition]
|
Drunk in Love [Preview] | 82 |
|
BEYONCÉ [Platinum Edition]
|
Flawless Remix [Preview] | 80 |
|
BEYONCÉ [Platinum Edition]
|
XO [Preview] | 79 |
 Dangerously In Love
Dangerously In Love
|
Crazy in Love [Preview] | 78 |
 I AM...SASHA FIERCE
I AM...SASHA FIERCE
|
Halo [Preview] | 78 |
|
BEYONCÉ [Platinum Edition]
|
Partition [Preview] | 78 |
 4
4
|
Run the World (Girls) [Preview] | 77 |
|
4
|
Love On Top [Preview] | 77 |
|
BEYONCÉ [Platinum Edition]
|
Haunted [Preview] | 76 |
This is a snapshot of the Beyoncé tracks most popular with American Spotify users, as of February 2015. As with the magic and convenience of Spotify's Related Artists endpoint, there's a similar tradeoff in using the Top Tracks endpoint: it's easy to get somewhat relevant tracks, unless the Spotify userbase acts in a way that don't gel with the way you (or your user) wants to listen to music.
As you can see, the top 10 tracks response is heavily weighted toward Beyoncé's most recent album. If we wanted to include only five tracks of Beyoncé's, choosing the five most popular from the top 10 tracks might give too narrow a range of her work (as 4 of those tracks are from her latest album). A more sophisticated algorithm might crawl the albums and tracks endpoints and then filter from the entirety of the artist's work.
So combine the decisions you have to make at the individual artist level (i.e. filtering their tracks) and at the related artists level (filtering for the most relevant artists), and you'll quickly find there's a lot of ways to tweak a music discovery algorithm.
Conclusion
That's enough of an introduction to the Spotify API; the endpoints described require no authentication. However, if you plan on making a more sophisticated program – including one that can read a user's playlists and actually create the playlist on their Spotify account – you'll want to go through the authorization process, which can be a little complicated.
I might cover that in another tutorial, for now, it's enough just to see the ways Spotify arranges and exposes its music data, and to contemplate how we can leverage the API to build a quick music discovery tool.