Week 4
Going forward, we'll be not just parsing and processing data, but turning it into something visible. Here's a simple use-case of image-production, which you can think of as a stepping-stone to building out an interactive website or graphic:
Montage the world from the command-line
It's also an example of the power of being able to parse data. The kind of website building we'll do isn't about hand-writing HTML, but thinking about the useful parts of data, including knowing how reliable and consistent it is, and how it ties into other datasets, and then leveraging our programming skills to efficiently organize the data for the Web.
Homework: More API practice, but maybe you'll find a job with it.
This week we look at conditional branching, one of the most important computer science fundamentals that we'll cover.
We'll also continue to look at APIs and getting more used to working with structured data, particularly JSON, as that format is nearly ubiquitous among modern APIs.
Class notes
- Check out the tools listing. Just about everything we'll use is listed here.
- Check out the curriculum listing
- No midterm (or final). Just progressively harder projects
- Lots more extra credit (as I have time to write them)
- Will try out Python maybe a couple weeks out from now…would rather everyone be generally comfortable with programming concepts (and code/data management) before we switch syntax.
Regarding the Twitter API
- Politiwoops: The Sunlight Foundation has a program that regularly checks the Twitter streams of politicians to see if they've deleted old tweets
- How to Spot a Twitter Spambot
- Indiana University's BotorNot project.
Clever uses of data
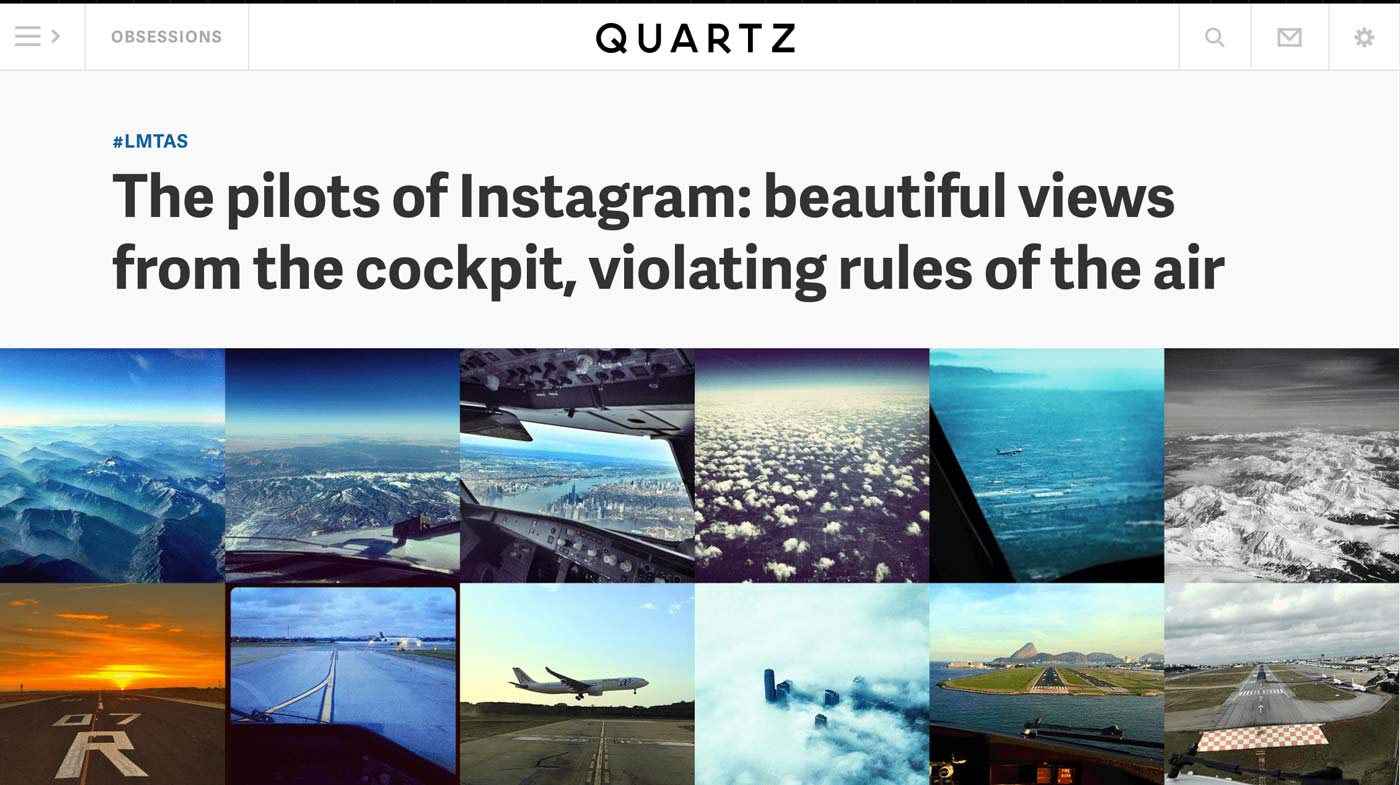
When it's easy enough to collect data, it becomes easier to explore, and to look things up: via Quartz's David Yanofsky, "The pilots of Instagram: beautiful views from the cockpit, violating rules of the air". And the reaction from pilots: Pilots have organized a ferocious, at times threatening, response to Quartz’s story about Instagrams in the sky
The limits of data
APIs don't expose all of a service's data. Twitter-related studies are frequently prone to being misinterpreted ("The Perils of Polling Twitter", by Jacob Harris).
Even when a company has full access to its data, it may not have run the most rigorous of algorithms on it. See Facebook's apology to Eric Meyer's complaint of Inadvertent Algorithmic Cruelty (and this anti-apology by a Guardian op-ed writer). If Facebook can make such an error while having full access to its own data, imagine where external analyses and studies might fail.
Conditional branching
We've been putting off learning about if/then/else statements because the programs we've been writing have been simple (and naive) enough to do without. But conditional branching is one of the most fundamental concepts in computer science. It enables us to design programs that take different paths based on runtime conditions.
What do we mean by "runtime conditions"? Consider the naive White House briefings scraper that we've written before:
# assume base_url=http://www.whitehouse.gov/briefing-room/press-briefings/
for i in $(seq 0 134); do
fname="$i.html"
echo "Downloading $fname"
curl "$base_url?page=$i" -o $fname --silent
done
A "runtime condition" would be the White House site going offline during the scrape, maybe between pages 70 to 80. Or maybe our hard drive momentarily reaches full capacity. To fix the problem, we can either manually download the un-fetched pages – tiresome (and unrealistic for larger batch jobs) – or just re-run the entire loop, which would be wasteful, and may run into runtime errors of its own.
But with an if/then condition, we can at least prevent the downloading of pages that already exist on the hard-drive. Here, the conditional expression checks to see if $fname exists on the hard drive and has a filesize greater than 0. If not, it attempts to download the page:
for i in $(seq 0 134); do
fname="$i.html"
if [[ -s $fname ]]; then
echo "Already exists: $fname"
else
echo "Downloading $fname"
curl "$base_url?page=$i" -o $fname --silent
fi
done
Or we could be a little more pro-active. If the site goes down (returns a 503 Service Unavailable) temporarily, we can instruct the loop to wait 5 minutes and retry the download:
# assume base_url=http://www.whitehouse.gov/briefing-room/press-briefings/
for i in $(seq 0 134); do
fname="$i.html"
# check the header
status_code=$(curl "$base_url?page=$i" --silent --head | head -n 1 | grep -oE [0-9]{3})
if [[ status_code == '503' ]]; then
echo "Temporary 503...will sleep for 5 min"
sleep 300
fi
echo "Downloading $fname"
curl "$base_url?page=$i" -o $fname --silent
done
Interesting JSON APIs
- USAjobs.gov
- Spotify
- New York Times:
- Sunlight Foundation
- Capitol Words - Word frequency count in Congress
- Congress
- Docket Wrench
- Foursquare
- Marvel Comics
- Google Maps
- Accuweather
- USGS Earthquake API
- NOAA Tides and Currents API
What is an API?
An Application programming interface is a set of routines and conventions for programmers to follow when accessing data, hardware, or other components of a computer/information system.
In the context of public-facing online services, such as through Twitter, an API allows programmers to access portions of data on behalf of a user – for example, having access to a user's list of retweets to build an app that purports to assess a user's viewpoints on gender equality. An API can be used to let programmers act on behalf of a user, such as the way Tweetdeck or Hootsuite can be used to schedule tweets.
For the purposes of this class, an API can be anything that we programmatically access. The New York Times homepage, www.nytimes.com, is technically an API, as the HTML document itself is an API, providing a pattern that can be used for extracting information.
e.g. using the pup parser (and curl) to extract top news headlines:
curl -s 'http://www.nytimes.com' | pup '#top-news h2 a'
Or to extract the bylines:
curl -s 'http://www.nytimes.com' | pup '#top-news .byline' | \
grep -vE '^ *[0-9]+' | \
grep -oP '[A-Z]+ (?:[A-Z]+\. )?[A-Z]+'
Or to just get the first names (in case you want to do a gender study)
curl -s 'http://www.nytimes.com' | pup '#top-news .byline' | \
grep -vE '^ *[0-9]+' | \
grep -oP '[A-Z]+ (?:[A-Z]+\. )?[A-Z]+' | \
grep -oE '^[A-Z]+'
We could get this information from the NYT's articles API:
Look at the USAJobs.gov API
Compare the USAJobs.gov website:
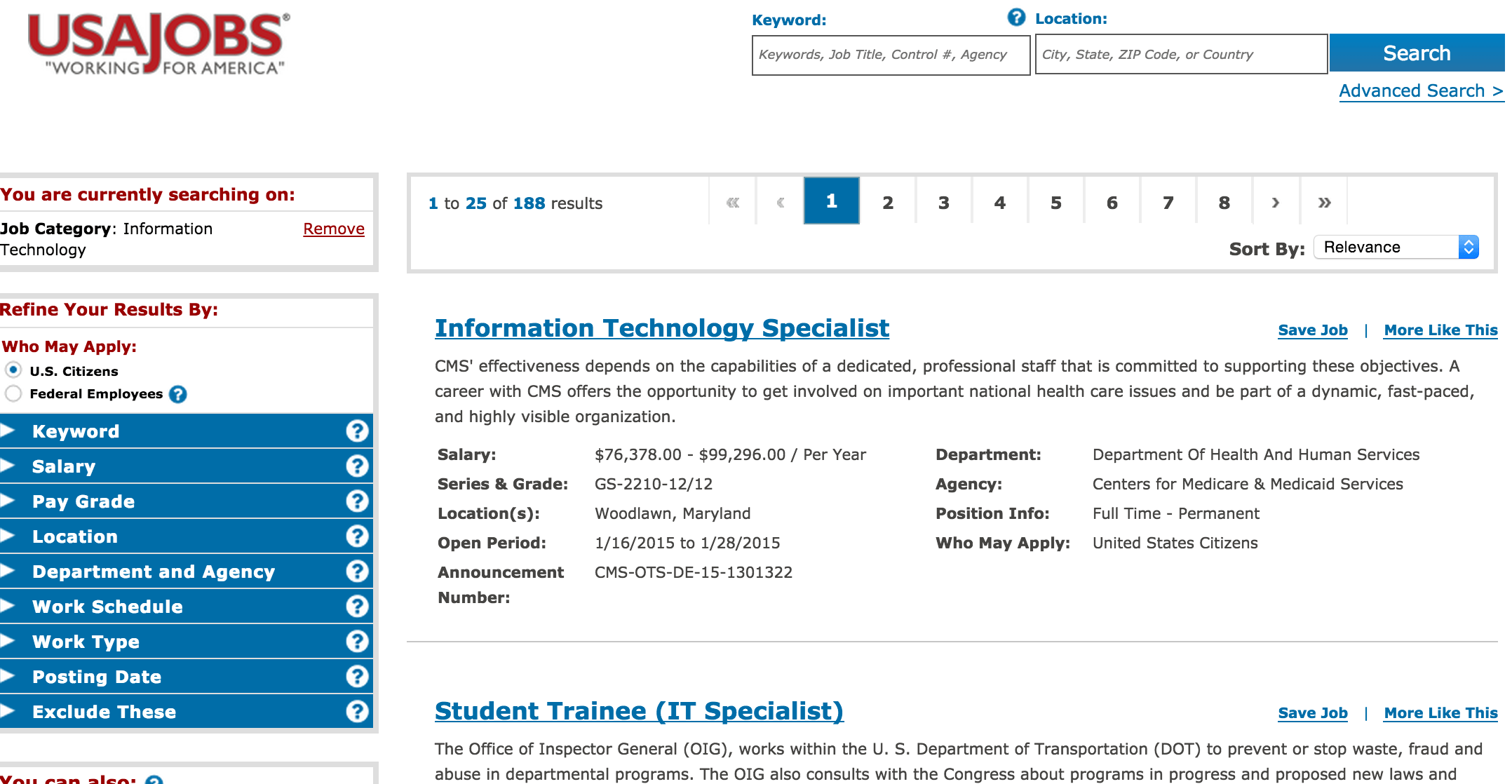
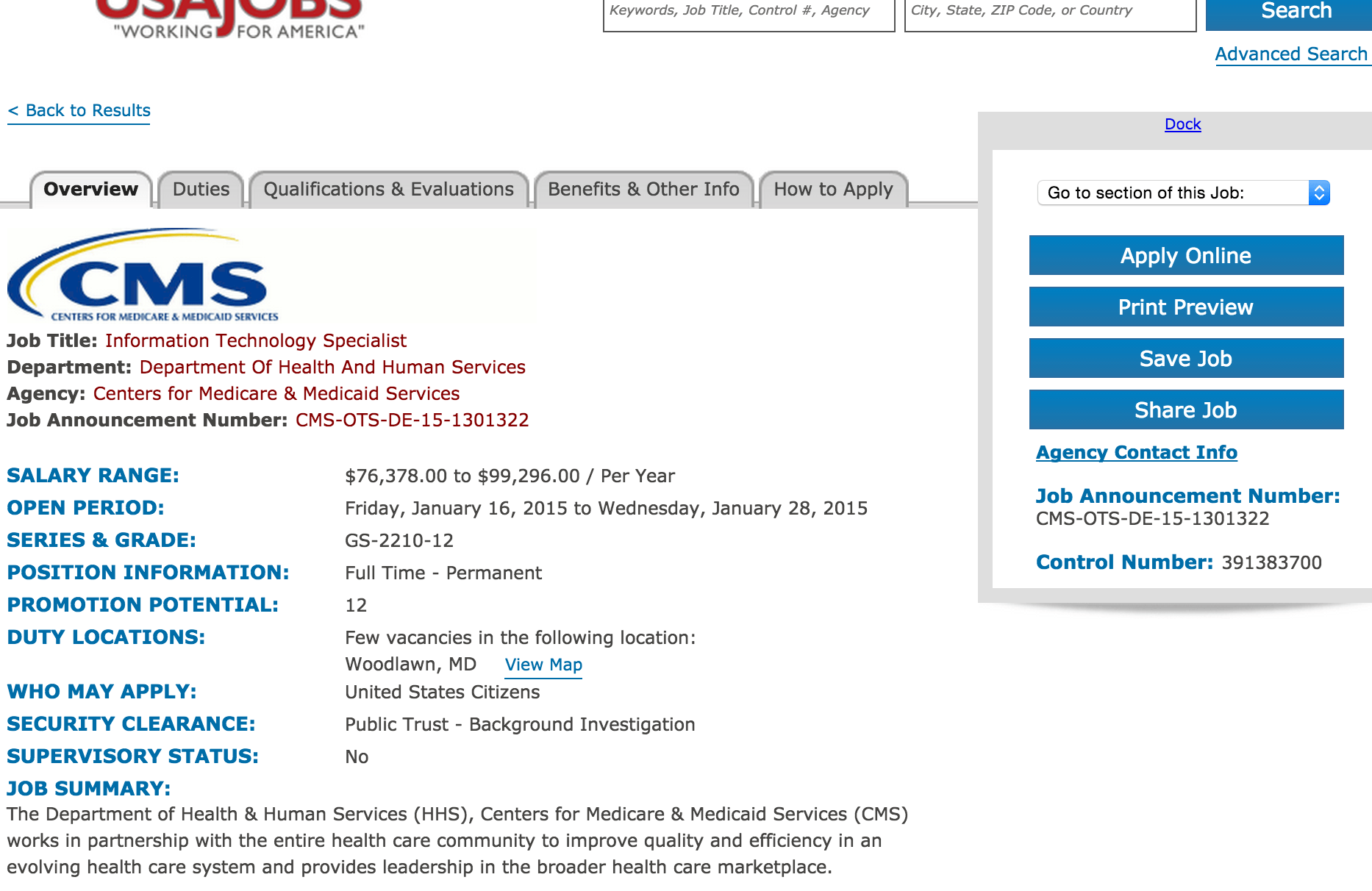
USAjobs.gov API
Compare that to the JSON API.
The response for 2200 category jobs:
{
"TotalJobs": "415",
"JobData": [
{
"DocumentID": "391383700",
"JobTitle": "Information Technology Specialist",
"OrganizationName": "Department Of Health And Human Services",
"AgencySubElement": "Centers for Medicare & Medicaid Services",
"SalaryMin": "$76,378.00",
"SalaryMax": "$99,296.00",
"SalaryBasis": "Per Year",
"StartDate": "1/16/2015",
"EndDate": "1/28/2015",
"WhoMayApplyText": "United States Citizens",
"PayPlan": "GS",
"Series": "2210",
"Grade": "12/12",
"WorkSchedule": "Full Time",
"WorkType": "Permanent",
"Locations": "Woodlawn, Maryland",
"AnnouncementNumber": "CMS-OTS-DE-15-1301322",
"JobSummary": "CMS' effectiveness depends on the capabilities of a dedicated, professional staff that is committed to supporting these objectives. A career with CMS offers the opportunity to get involved on important national health care issues and be part of a dynamic, fast-paced, and highly visible organization. For more information on CMS, please visit: http://www.cms.gov/ . This position is located in the Department of Health & Human Services (HHS), Centers for Medicare & Medicaid Services (CMS), Office of Technology Solutions (OTS), Woodlawn, MD. WHO MAY APPLY: This is a competitive vacancy, open to all United States Citizens or Nationals, advertised under Delegated Examining Authority....",
"ApplyOnlineURL": "https://www.usajobs.gov/GetJob/ViewDetails/391383700?PostingChannelID=RESTAPI"
}
],
"Pages": "2"
}