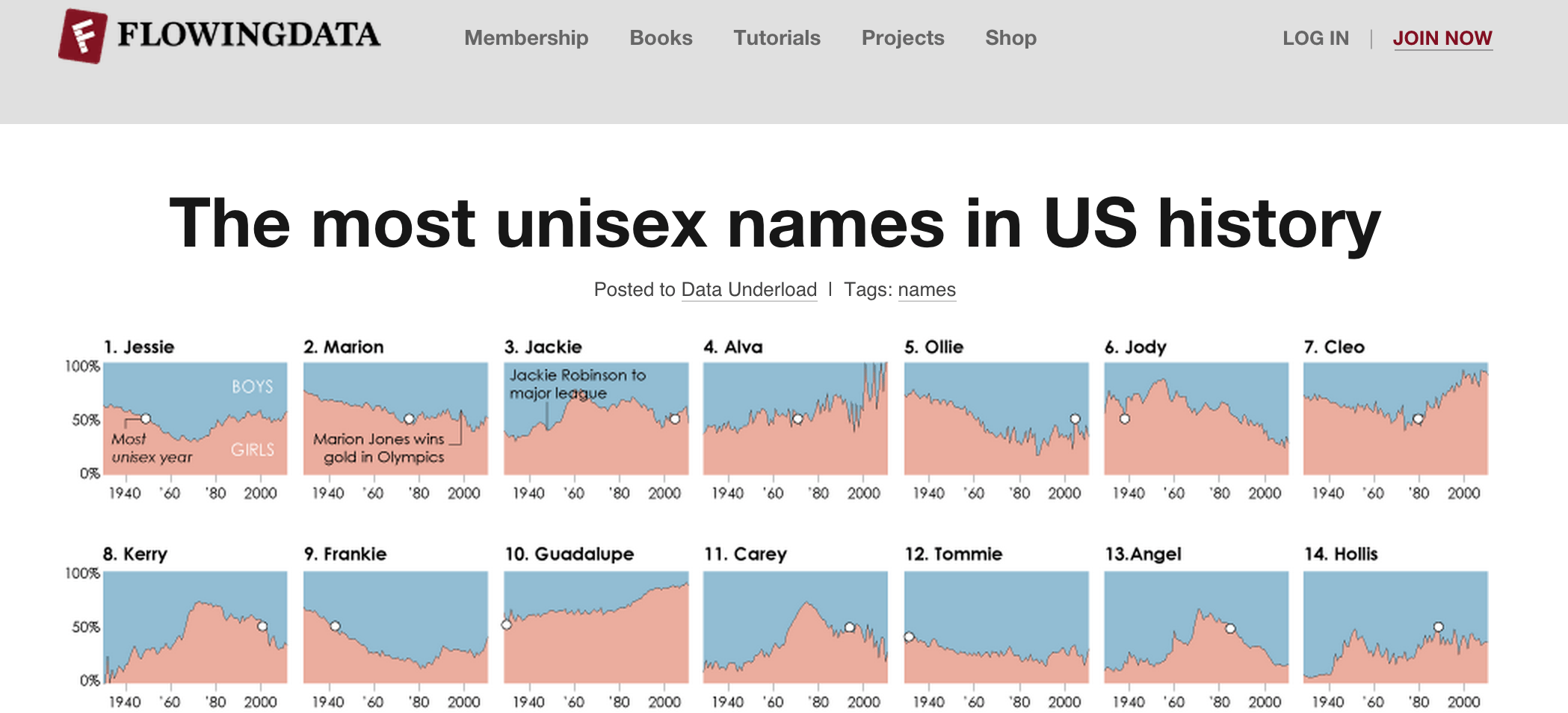
Using baby names to classify names by gender
By now, you might be very familiar with the U.S. Social Security Administration’s data on most popular baby names. Instead of just analyzing the data, let’s put it to use. With simple if/else logic, and the SSA data, we can design a crude program to guess the sex of a person based on their first name, and the frequency of that name among babies according to the SSA data. Whether or not the guess is right will be more an example of the limits of data rather than computational cleverness.
Deliverables
A project folder named homework/baby-name-gender-detector
In your compciv repo, create a subdirectory:
./homework/baby-name-gender-detector
And a data-hold dir:
./homework/baby-name-gender-detector/data-hold
helper.sh to download the SSA baby data and extract a sample
Create:
./homework/baby-name-gender-detector/helper.sh
The helper.sh script should download the SSA nationwide baby name data into data-hold/ and unzip only two files :
./homework/baby-name-gender-detector/data-hold/yob1973.txt./homework/baby-name-gender-detector/data-hold/yob2013.txt
And then combine them into one file:
./homework/baby-name-gender-detector/data-hold/namesample.txt
This step will already have been written for you in the instructions below.
The classifier.sh script to classify names as `M` or `F`
Create:
./homework/baby-name-gender-detector/classifier.sh
When run from the command-line, like so:
bash classifier.sh Marion Lucy Jessie Casey Zarkkon
The classifier.sh script should produce this exact output:
Marion,F,50,798
Lucy,F,100,4261
Jessie,M,57,1902
Casey,M,65,2825
Zarkkon,NA,0,0
Note how the output follows these conditions:
-
Each line contains comma-separated values:
- Name
- Gender
- Percentage of babies with that name and gender
- Total babies with that name
- The line
Lucy,F,100,4261is read as: 100% of the 4,261 babies named Lucy were girls - The line
Jessie,M,57,1902is read as: 57% of the 1,902 babies named Jessie were boys. - In the case of a tie, i.e. 50/50, print
Fin the Gender column - In the case where no babies have a given name, i.e.
Zarkkon, printNAfor gender, and0for the other two columns, e.g.Zarkkon,NA,0,0
Zero arguments
One more requirement: if classifier.sh is run with no arguments:
bash classifier.sh
It needs to output an error message:
Please pass in at least one name
Background
The SSA Baby Name Data contains a wealth of interesting information about popular trends in names over time, as America's culture and diversity changed.
Below is a streamgraph of "Unisex names history" by FlowingData.com
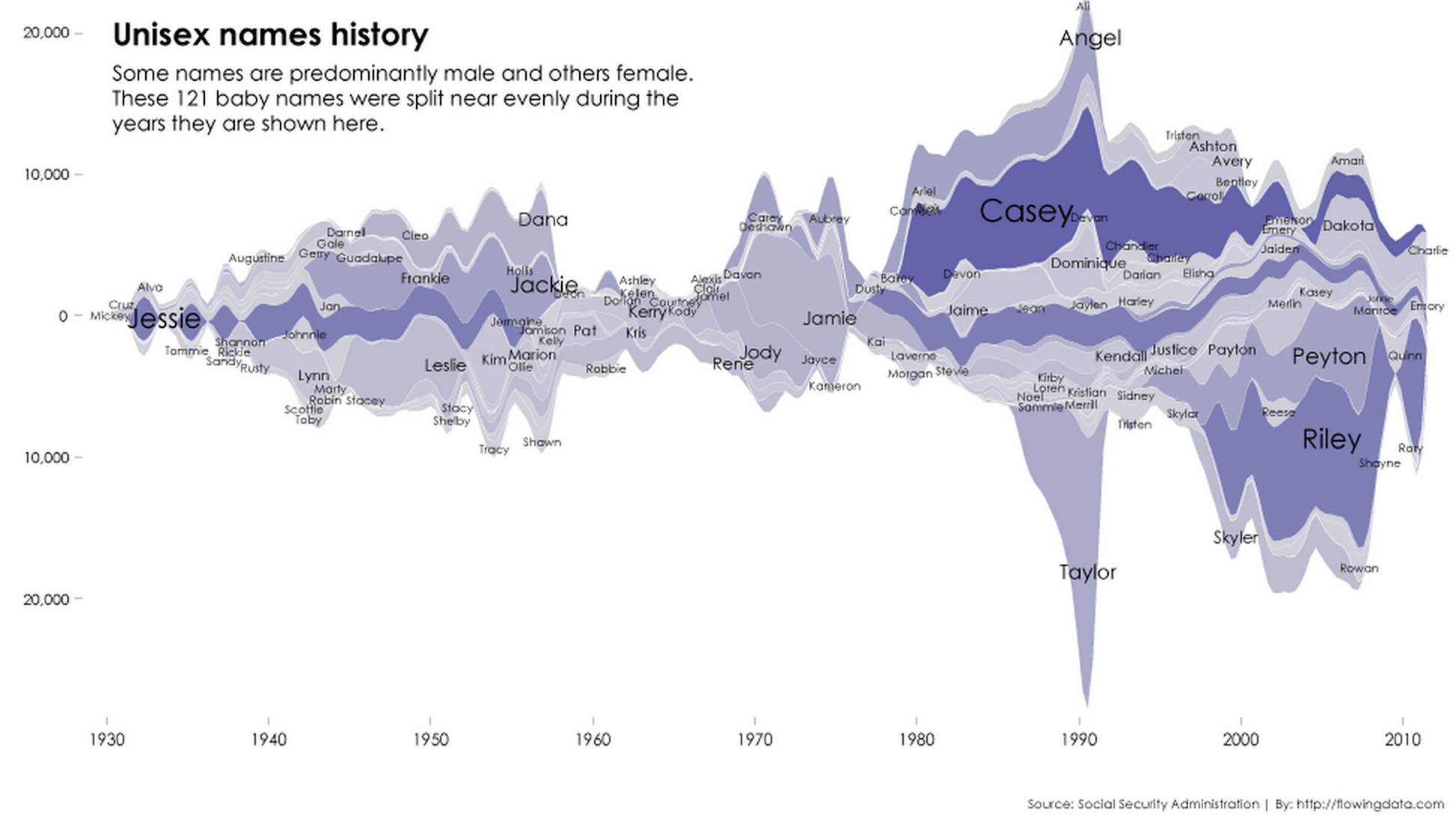
The data also serves as a starting point for creating a heuristic for guessing the sex of a person by first name, at least for an American-born citizen. Why would this be interesting? There have been numerous studies conducted to compare the representation of men and women in the media, both as reporters and editors, and also as sources quoted in stories. Software can at least help filter for ambiguous names to be manually researched when doing a survey count.
In 2013, the Knight-Mozilla OpenNews Source project interviewed the creators of the Open Gender Tracker, an attempt to "develop automated gender analytics for the news." And check out the "Who Writes for the New York Times?" project, which uses Census data to automatically guess/classify the sex of bylines featured on the front page of nytimes.com.

Better data
The gender_detector Ruby library, maintained by Brian Muller, uses data from the command-line gender program that is deeper than just U.S baby names.
On his Github repo, Muller fielded some interesting discussion about why such a library would be useful. And on his blog, he wrote what I consider one of the best reflections on responsibility in open-source software development (a topic tangential to this class).
There is also the gender-detector Python library in development by Marcos Vanetta, for use in the Open Gender Tracking project.
Note: For this assignment's namesample.txt, we arbitrarily choose the data from 1973 and 2013 as the basis to compare baby name trends. We could use different years, or even the entire set, but this sample works for our purposes.
Hints
You'll want to be comfortable with these concepts:
For helper.sh
I've already written this for you. The SSA Baby data was likely generated on Windows machines, which hasn't caused an issue so far in our analyses. However, the way that Windows handles the end-of-a-line is different than how UNIX (and OS X) does, which can be extremely aggravating if you're not aware of the difference. The corn.stanford.edu machines have a dos2unix utility that takes care of the conversion.
This isn't an exercise in operating system differences, so just use the code below. But observe how I've specified the exact two files needed for the namesample.txt, and unzipped only those, and, using unzip -p, piped the content of those files directly into namesample.txt
# ~/compciv/homework/baby-name-gender-detector/helper.sh
mkdir -p ./data-hold
cd data-hold
# download the file into names.zip
curl -o names.zip http://stash.compciv.org/ssa_baby_names/names.zip
# unzip directly into standard output and convert via dos2unix
unzip -p names.zip yob1973.txt yob2013.txt | dos2unix > namesample.txt
# move back up to homework/baby-name-gender-detector
cd ..
The sex-classifying logic in classifier.sh
Try one name at a time
Though the deliverables call for a script that can classify multiple names, I suggest starting out as if all you had to do was classify a single name:
name=Jessie
Loops and branches in loops and branches
The branching and looping-logic here can be quite complicated. You should expect to have a for-loop within another for-loop, and at least a couple of if-statements, perhaps one inside another.
(It's also possible to write this program without any loops, though that requires more pipe-hackery than it's worth for such a small prototype project).
Below, I've included 80% of a possible solution. You can copy it (I would copy it by hand, to slow down enough to get a feel for the logic) and alter it as you wish. It satisfies the requirements except for:
- Some branches simply have an
echo "You need to do something here"statement. You should fill in the code as appropriate. - If a given name, such as
Zarkkon, has 0 boys or girls, you need to handle that specific condition. Otherwise, the sample code I've given you will throw an error when it tries to divide by zero. The most straightforward way is to use another if-statement somewhere - The
classifier.shscript needs to be able to take an arbitrary number of names as arguments (I cover this in section below) - You need to write the conditional statement for when 0 arguments are passed in.
The partial classifer.sh code:
# this script expects `helper.sh` to have created a
# file at ./data-hold/namesample.txt to use
datafile='data-hold/namesample.txt'
# for now, set name to a constant
name=Jessie
# this step matches every line with the $name followed
# immediately by a comma
# So that "Pat" doesn't match "Patrick" and "Patty"
name_matches=$(cat $datafile | grep "$name,")
# we'll set up a couple of variables at 0
# and for each value in $name_matches, sum up the
# baby count by gender
m_count=0
f_count=0
# for each value in $name_matches
for row in $name_matches; do
# get the baby count, which is in the third column, i.e.
# Jessie,F,999
# and set it to the `babies` variable
babies=$(echo $row | cut -d ',' -f '3')
if [[ $row =~ ',M,' ]]
then
# if the row is for male babies,
# add to $m_count
# Note that in shell arithmetic, you don't have to use
# the dollar sign to reference the variables
m_count=$((m_count + babies))
else
##### HEY YOU
# You fill in the code here. Should
# be similar to the branch above
echo 'You should do something here for girl babies'
fi
done
# The for-loop needed to sum up the babies is done
# let's calculate a percentage of babies that are female
# and make it a whole number, i.e.
# num_of_girl_babies
# divided by (boys + girls), then multipled by 100
total_babies=$((m_count + f_count))
#### NOTE:
# This next step will result in an ERROR if both
# $m_count and $f_count are 0. Another way to think
# of it is that $name_matches, which was used for the
# for-loop, is empty.
#
# (also, remember you have to print something like:
# Zarkkon,NA,0,0
# for the no-boys-or-girls scenario)
#
# Either way, you need some kind of conditional branching
# to deal with that situation before you reach this next
# command or you will get an error:
pct_female=$((100 * f_count / total_babies))
# If the percentage is greater to or equal to 50
if [[ $pct_female -ge 50 ]]; then
g_and_pct="F,$pct_female"
else
##### HEY YOU
# You fill in the code here. Should
# be similar to the branch above
echo 'You should do something here when boys make up the majority'
fi
# If you've fixed the code properly, and name=Jessie,
# this line should print out:
# Jessie,M,57,1902
echo "$name,$g_and_pct,$total_babies"
# When that works, remove the hardcoded $name value and move
# on to the next step of modularizing the script
My partial classifier.sh is not elegant or efficient, but it's pretty straightforward. You don't have to start from it. And even if you do, there's plenty of freedom in how you might add/alter the logic (note: if you do use my code, you shouldn't have to radically alter it, so I don't expect you to go too far off the range).
Modularizing the classifier.sh
You might know how to run a shell script from the command line and pass in 2, 3, or even 4 different arguments…but how about an arbitrary number of arguments?
Check out this StackOverflow Q&A: How to iterate over arguments in bash script.
Here's an outer-loop that may/should work for you. Feel free to use it:
for name in "$@"; do
echo "What's in a $name?"
# do your actual stuff in here...
# ...
done
Checking for zero arguments
Don't forget that if classifier.sh is run with zero arguments, you need to output an error message: Please pass in at least one name
There are several ways to do this, including checking to see if $1 contains anything. Check out the GNU documentation for conditional expressions to see how to test the length of a string.
About that if statement…
In the sample classifier.sh code I provide, you might have noticed this strange conditional expression:
if [[ $row =~ ',M,' ]]
then
#...
fi
That equals-tilde evaluates to true if the right-side value (in this case, $row) would be a regular expression pattern that would match the left-side value (in this case, ',M,'). If your regex knowledge is a bit hazy, you might still recognize that ',M,' does not contain any regex metacharacters. In other words, we are trying to match the literal value of ,M,, which is present for rows pertaining to boy babies, e.g.
Robert,M,7200
This is a long way of saying: the regex-conditional, [[ $something =~ $some_pattern ]] is over-powered for this use-case. But who cares (for now)? I chose this conditional expression because it's the simplest to understand among the comical number of ways that you could test to see if a line (i.e. $row) contains a literal value (i.e. ',M,').
Check this StackOverflow discussion about "String contains in bash" to see all the alternative methods you could try.
Solution
One modification to the example code above:
name_matches=$(cat $datafile | grep "$name,")
This will wrongly match partial names against input such as n or an, which would pick up Dan and Adrian, among many other names. We have to use a word boundary or beginning-of-line operator to prevent this. Also, if we want to match input case-insensitively, such as dan, we use the -i option:
name_matches=$(cat $datafile | grep -i "^$name,")
if [[ -z $1 ]]; then
echo 'Please pass in at least one name'
fi
for name in "$@"; do
# this step matches every line with the $name followed
# immediately by a comma
# So that "Pat" doesn't match "Patrick" and "Patty"
name_matches=$(cat data-hold/namesample.txt | grep -i "^$name,")
if [[ -z $name_matches ]]; then # no matches made
echo "$name,NA,0,0"
else
m_count=0
f_count=0
for row in $name_matches; do
# get the baby count
babies=$(echo $row | cut -d ',' -f '3')
if [[ $row =~ ',M,' ]]
then
m_count=$((m_count + babies))
else
f_count=$((f_count + babies))
fi
done
# done summing up m_count and f_count
pct_female=$(( 100 * f_count / (m_count + f_count) ))
if [[ $pct_female -ge 50 ]]; then
str="F,$pct_female"
else
str="M,$((100-pct_female))"
fi
echo "$name,$str,$((f_count + m_count))"
fi
done