Analyzing Tweets in CSV form
Using the command-line t program to collect Twitter data as CSV and the csvfix tool to process it, we can then parse the text using the standard Unix text tools to find interesting trends in a user’s tweets.
The t program is a simplified wrapper for the Twitter API; while it makes connecting to Twitter easy, the data it returns is only a subset of what Twitter’s API offers. That said, enough data is revealed in the text alone, and so this exercise will mostly be a practice of grep and regular expressions. Please, especially, review your regular expressions.
Make sure you’ve completed the instructions on how to sign up with Twitter as a developer and get authenticated.
Deliverables
The timeline-csv-analysis.sh script
In your existing congress-twitter folder, create a script named timeline-csv-analysis.sh
This is what your repo will look like:
|-compciv/
|-homework/
|--congress-twitter/
|--timeline-csv-analysis.sh
|--data-hold/
|--someusers-tweets.csv
Note that you already have a congress-twitter folder, from a previous assignment.
The timeline-csv-analysis.sh script, when run, will do the following:
- Using the t program, it will collect the maximum number of tweets possible from the live Twitter API from a given user’s timeline in CSV format.
-
Using the csvfix program, calculate the following:
- Top 10 hashtags, case-insensitive, in order of frequency of appearance.
- Top 10 users by frequency of retweets
- Top 10 users mentioned in tweets that are NOT retweets and who are NOT the user in question.
- Top ten words, 5-letters or more, that are not usernames, nor hashtags, nor URLs.
Usage:
bash timeline-csv-analysis.sh DarrellIssa
Output:
Fetching tweets for DarrellIssa into ./data-hold/DarrellIssa-timeline.csv
Analyzing 3201 tweets by DarrellIssa since "2013-11-19 17:27:24 +0000"
Top 10 hashtags by DarrellIssa
246 #irs
126 #irstargeting
125 #obamacare
101 #americasvets
78 #benghazi
55 #fastandfurious
54 #doj
54 #dataact
48 #atf
44 #militarymonday
Top 10 retweeted users by DarrellIssa
116 @gopoversight
28 @speakerboehner
13 @gopleader
12 @housegop
8 @repmarkmeadows
6 @jim_jordan
5 @datacoalition
4 @sorefeetmt
4 @joshmyersnc
4 @egil_skallagrim
Top 10 mentioned users (not including retweets) by DarrellIssa
214 @gopoversight
27 @jim_jordan
16 @housejudiciary
15 @speakerboehner
12 @tgowdysc
12 @gopleader
11 @wsj
11 @repcummings
11 @foxnews
10 @usmc
Top tweeted 10 words with 5+ letters by DarrellIssa
301 shall
195 lerner
181 about
175 president
164 house
152 hearing
145 congress
137 today
135 states
113 state
Another example:
bash timeline-csv-analysis.sh CoryBooker
Output:
Fetching tweets for CoryBooker into ./data-hold/CoryBooker-timeline.csv
Analyzing 3201 tweets by CoryBooker since "2014-10-24 01:28:29 +0000"
Top 10 hashtags by CoryBooker
46 #sotu
22 #fusionriseup
20 #vegan
20 #givingtuesday
14 #smallbizsat
13 #nj
11 #netneutrality
8 #souls2polls
8 #gotv
7 #stateofcivilrights
Top 10 retweeted users by CoryBooker
12 @whitehouse
9 @silviaealvarez
8 @senbookerofc
8 @ghelmy
7 @stevenfulop
7 @senangusking
7 @brendanwgill
6 @steveadubato
6 @senrandpaul
6 @quorumcall
Top 10 mentioned users (not including retweets) by CoryBooker
19 @tomhilly
14 @swayneharris
14 @progressagent
13 @tw22197
12 @ramya_bal
11 @jwhof
11 @arielkelisb
10 @savecatstoday
10 @onecaliberal
10 @johnbetz2
Top tweeted 10 words with 5+ letters by CoryBooker
429 thanks
359 thank
172 great
171 about
167 vegan
121 today
116 support
115 senator
105 please
105 booker
See the following section for hints and requirements.
Hints
Set up the t program and connect to Twitter's API
The very first thing you need to do is install Ruby on your corn.stanford.edu account and install the t program. Then you need to authenticate with Twitter's API.
The instructions are here. This is a task that could take about 30 minutes (waiting for things to finish installing), so start as soon as you can. By the end of it, you should be able to Tweet from the command-line, among other things.
Check out t's documentation. To download the maximum number of tweets from a user's timeline:
t timeline -n 3200 some_user_name
Sample output:
@dancow
Hyperlocal news network Patch finds profit after laying off most of its
employees http://t.co/uei2o3Yose
@dancow
Daily Beast reporter doesn't know about Updog http://t.co/6Llk0xdPO2
@dancow
I'll be honest...the entire CSS Flexbox thing has totally slipped by my radar
. Time to put myself out to pasture http://t.co/pscKS7zydb
However, this is not the data format we want (as you can imagine, it'd be a pain in the ass to grep). So use the --csv option. And redirect to a file.
t timeline -n 3200 --csv some_user_name > data-hold/some_user_name.csv
Note that Excel can be used to open up CSV files. So you can send the output to your ~/WWW directory and download the file onto your desktop (you could also set up t to work on your own laptop, if you wanted).
In Excel, this is what the data looks like:

The data returned by the t program is much less specific than what we would get from the Twitter API as JSON. But given all that we care to count: hashtags, users who are retweeted, users who are mentioned, and word counts, we only need the Text field.
If you want pre-fetched data to work with, here's a couple of archives:
Working with t's data
As I said before, the t program shows only a subset of fields from the actual Twitter JSON API. There's no columns that say, "This tweet is a retweet", or, "This tweet is a reply". So you will have to use grep to make that judgment based on text patterns.
What is a retweet?
A retweet is any Tweet that starts with a RT. Here's an example Tweet text from Darrell Issa's tweets-as-CSV:
RT @RepLankford: Chaired informative @GOPoversight hearing yesterday on #SSDI & ways to save the program from insolvency in 2016 http://t.co/hyNZEfphYB
What is a mention?
Anytime a user mentions another user, they prepend an @ in front of the username (remember that all Twitter usernames consist of alphanumerical characters and underscores).
The following Tweet mentions two users, @SDSU and @GoAztecs:
Congrats to the @SDSU Aztecs on winning the Mountain West Conference this past weekend! #MarchMadness @GoAztecs #WeAreAztecs
What is a Hashtag
A Hashtag is any sequence of alphanumerical characters, and underscores, that immediately follow a pound sign, #. The above tweet contains two hashtags, #MarchMadness and #WeAreAztecs
Install csvfix
The csvfix tool is yet-another-parser designed specifically for the parsing of comma-delimited files, which is the data format that we'll be fetching from Twitter using t.
You can find installation and usage information about csvfix here.
You should be wondering, why can't we just use cut and grep, e.g.
echo "something,apples,oranges" | cut -d ',' -f 1,2
However, remember that cut, as does grep, work on a line by line basis. But some tweets contain text that are more than one line:

Or, more to the point, text that contains commas, which completely messes up with your ability to cut and delimit by literal commas:
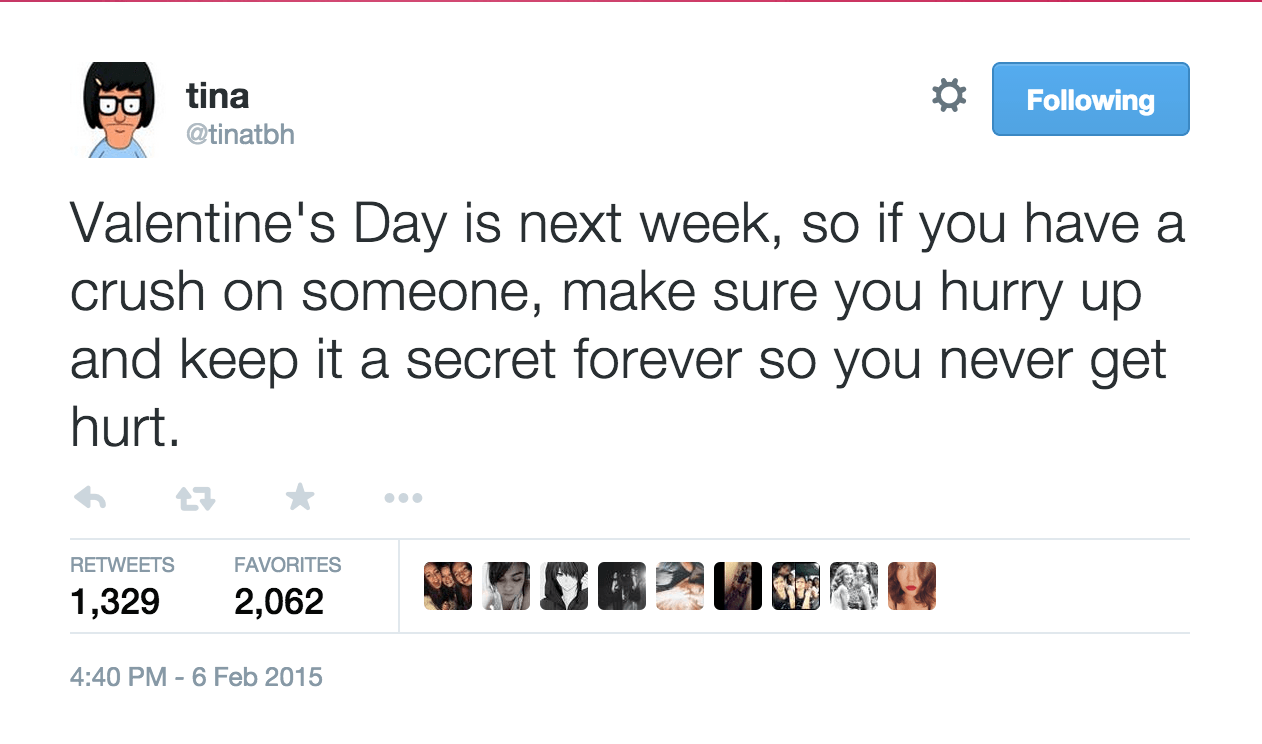
In a CSV file, these tweets look like this:
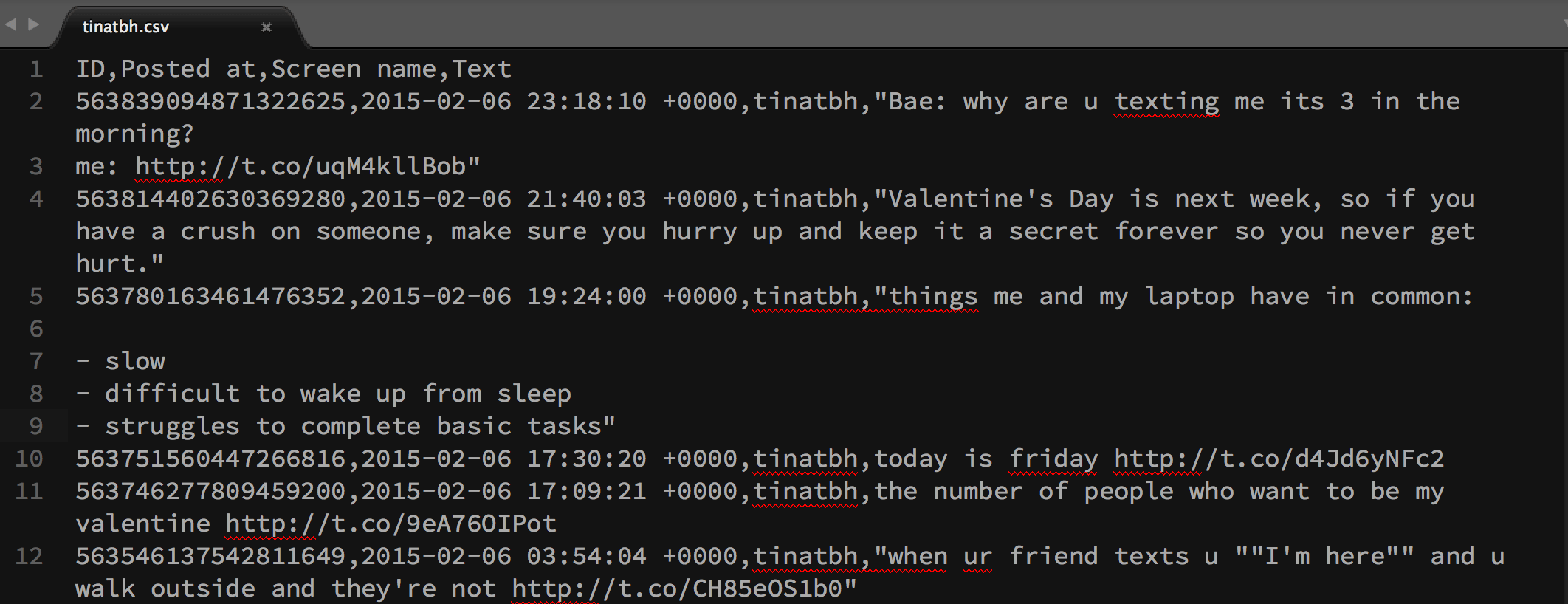
So think of csvfix as a parser sophisticated enough to deal with all of the ways that CSV get get messy. Check out its entry in the Unix tools page for examples and installation.
Getting started
The assignment requires that timeline-csv-analysis.sh print out these lines (assuming you're looking at user "DarrellIssa"):
$ bash timeline-csv-analysis.sh DarrellIssa
Fetching tweets for DarrellIssa into ./data-hold/DarrellIssa-timeline.csv
Analyzing 3201 tweets by DarrellIssa since "2013-11-19 17:27:24 +0000"
You can infer two things:
- Every time you run the script and give it a username, a new file named
data-hold/some_username-timeline.csvis created. - After the tweets are downloaded, you have to count how many tweets there are as well as the date of the oldest tweet in the collection.
Here's the first few lines for timeline-csv-analysis.sh:
# This assignment is just for readability purposes
username=$1
# create data-hold if it doesn't already exist
mkdir -p ./data-hold
echo "Fetching tweets for $username into ./data-hold/$username-timeline.csv
"
# use t to download the tweets in CSV form and save to file
file=data-hold/$username-timeline.csv
t timeline -n 3200 --csv $username > $file
# Get the count of lines using csvfix and its order subcommand
# note: another subcommand could be used here, but the point is to use
# csvfix to reduce the file to just the first field, and then count the lines.
# In other words, you cannot just count the number of Tweets with wc alone,
# because some tweets span multiple lines
count=$(csvfix order -f 1 $file | wc -l)
# The timestamp of the tweet is in the field (i.e. column) named, 'Posted at'
# and the oldest tweet is in the last line
lastdate=$(csvfix order -fn 'Posted at' $file | tail -n 1)
# Echoing some stats about the tweets
echo "Analyzing $count tweets by $username since $lastdate"
Solution
mkdir -p "./data-hold"
file="./data-hold/$1-timeline.csv"
rm -f $file # delete it just in case it exists
echo "Fetching tweets for $1 into $file"
t timeline $1 --csv -n 3200 > $file
count=$(csvfix order -f 1 $file | wc -l)
lastdate=$(csvfix order -fn 'Posted at' $file | tail -n 1)
echo "Analyzing $count tweets by $1 since $lastdate"
echo "Top 10 hashtags by $1"
csvfix order -fn Text $file | tr '[:upper:]' '[:lower:]' | grep -oE '#[[:alnum:]_]+' | sort | uniq -c | sort -r | head -n 10
echo "Top 10 retweeted users by $1"
csvfix order -fn Text $file | grep -oE 'RT @[[:alnum:]_]+' | tr '[:upper:]' '[:lower:]' | grep -oE '@[[:alnum:]_]+' | sort | uniq -c | sort -r | head -n 10
echo "Top 10 mentioned users (not including retweets) by $1"
csvfix order -fn Text $file | grep -vE '\bRT\b' | \
tr '[:upper:]' '[:lower:]' | \
grep -vi "@$1" | \
grep -oE '@[[:alnum:]_]+' | sort | uniq -c | sort -r | head -n 10
echo "Top tweeted 10 words with 5+ letters by $1"
csvfix order -fn Text $file | \
tr '[:upper:]' '[:lower:]' | \
sed -E 's/@[[:alnum:]]+//g' | \
sed -E 's/#[[:alnum:]]+//g' | \
sed -E 's/http[^ ]+//g' | \
grep -oE '[[:alpha:]]{5,}' | sort | uniq -c | \
sort -rn | head -n 10