Basic word analysis of the White House Press Briefings
This time, we gather the actual WH briefing webpages (starting from the list pages we downloaded in the previous assignment). And we use grep to do some rudimentary data scraping.
Deliverables
The top ten words in White House Press Briefings
At the end of this assignment, you should have a folder named wh-briefings, with more than 1,300 HTML files for the Obama administration’s White House briefings.
Email me a list of the top 10 words, in order of frequency, that are seven letters or longer, used in all of the briefings.
Use the subject line: Top 10 WH Words via Grep
Save your code for now. We’ll worry about getting it on Github later.
The purpose of this assignment is to get familiar with two practical concepts in computing:
- Searching for and isolating patterns in text
- Executing a task in the background (or offline)
Here are several relevant guides that I've created:
- A review of the pipes and filters concept
- How to grep
- Basic regular expressions
- How to write a basic shell script
- How to run a process in the background
You should by now have a folder containing the listings of White House briefings, if you finished the previous assignment. If not, feel free to download my archive here:
http://stash.compciv.org/wh/wh-press-briefings-listings-2015-01-07.zip
Hints
You should break this task up into at least 3 discrete steps:
-
A way to parse the HTML you downloaded in the previous exercise, and extract the URLs for each individual briefing, e.g.
http://www.whitehouse.gov/the-press-office/2015/01/07/press-gaggle-press-secretary-josh-earnest-en-route-detroit-mi-010715 - A scraper that will
curldown every briefing and save it to the hard drive. - A way to extract the relevant text from each briefing page, and then performing the word count on just that text (and not on the boilerplate template code or HTML of each page).
I would recommend creating a script for each step, you can even just call them step1.sh, step2.sh, step3.sh.
Note: If making three files to store what seems like small snippets of code feels like overkill, then you don't have to do it…if you like copying and pasting things from a text file. Go for it. And remember, you can also use the history command to see past commands you've done.
Step 1. Extract URLs for each individual briefing
Note: to do this step, you'll need to have all of the pages you downloaded in the previous assignment. You can download and work from my archive here.
The basis of this first step is similar to the previous homework: you need to get all the relevant URLs to run through a for loop to curl them down. Unfortunately, unlike the previous homework, you can't just iterate through a sequence of numbers.
Use the source, Luke
If you're new to HTML, it's worth scouting out the situation in your browser. Visit one of the briefing listings on the White House site and view the source HTML (on Chrome, you can right-click to bring up a pop-up menu, and then select View Source ):
This will bring up the raw HTML in the browser, which in Chrome, is not too painful to read:
Let's browse the raw HTML via the command-line.
Assuming you have the resulting pages of the last assignment in a subdirectory named wh-listings, grep any one of the pages for href (which is part of the raw HTML code use to designate a URL) and then count the lines with wc:
grep 'href' wh-listings/1.html | wc -l
On a typical page, you'll find more than 240 links. Just by viewing each briefings listing, you should be able to eyeball that there are just 10 actual briefings per page.
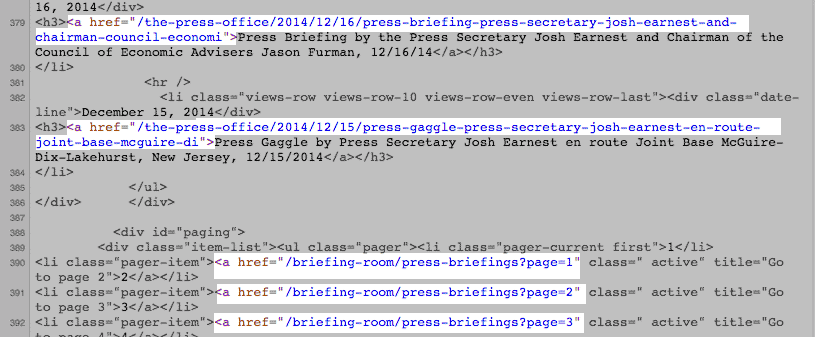
So to complete this step, you need a method that extracts a pattern of text, i.e. the relevant part of this HTML code:
<a href="/the-press-office/2014/12/18/press-briefing-press-secretary-josh-earnest-121814">Press Briefing by the Press Secretary Josh Earnest, 12/18/14</a>
Also, you need a way to pick just the 10 relevant links: look at each URL and you should be able to find a common pattern within the briefing urls.
You'll need to understand how to use grep with regular expressions (my tutorial on grep and on regexes).
You'll know that your program works when, given any one of the briefings-listings page, it outputs just 10 URLs.
Hint: On the raw HTML of the White House pages, they use relative URLs. For example, this is an absolute URL:
http://www.whitehouse.gov/the-press-office/some-page.html
The "relative" version of this URL would be:
/the-press-office/some-page.html
You can curl the absolute URL, but not the relative one.
So uou need to fix the relative URLs gathered from the White House HTML so that they're absolute (it's the same pattern for all of them).
Step 2. Curl them all
In the previous step, you should have a list of all the URLs of press briefings (hint: it's in the neighborhood of 1,300+).
Now you just need to run a for loop to curl each URL, just as you did in the previous homework assignment. There's one main difference: you probably won't be able to save each page as something like 1.html, 2.html, etc. as you did previously.
However, you can't save a file named "/2015/01/09/press-gaggle-principal-deputy-press-secretary-eric" directly to your hard drive, not without creating all the intermediary subdirectories, which is a pain. I think the easiest thing to do is to replace all of those forward slashes (i.e. /) with some other character (any character) that can normally be part of a file name (however, I would not replace those slashes with a space. Or any other punctuation for that matter).
If you've read through the tutorials mentioned previously, you should be very familiar with a tool that can translate one character to another.
At the end of Step 2, you should have 1,300+ webpages in a directory. First of all, I'd run Step 2 in its own empty directory. Second, I would definitely make Step 2 its own script and then run it in the background, so that it keeps scraping after you log off of corn.stanford.edu.
Note 1: You don't have to learn how to run a task in the background. And if it seems to abstract for you right now, then do this part the way you've done things before: execute the code, and leave your laptop on. It might be a few hours though before you can log off…
Note 2: If you do want to try running the task in the background, and you want to know when it's finally done…add a command to the script, at the bottom, that emails you:
echo "Hey I'm done. Hooray" | mail YOURSUNETID@stanford.edu
Hint: Thinking about the for loop
The trick here is to understand a little bit about command substitution. In the solution to the previous homework, which looked like this:
for i in $(seq 0 134); do
curl "http://www.whitehouse.gov/briefing-room/press-briefings?page=$i" \
-s -o "$i.html"
done
– you should've noticed what seq 0 134 actually did. If you aren't sure about it, execute that command by itself and see what you get.
So for this part of the current homework, instead of looping through numbers 0 to 134, you are looping through a collection of (relative) URLs…so it's not as simple as substituting a number in ?page=$i…but it's pretty much the same pattern.
You'll still be doing a curl in that for loop, but you'll be looping across a different collection (and you'll be saving to a filename that's not just a number, i.e 52.html).
Another way to think of it. The answer to the previous homework could look like this:
vals=$(seq 0 134)
for i in $(vals); do
curl "http://www.whitehouse.gov/briefing-room/press-briefings?page=$i" \
-s -o "$i.html"
done
So now, you just need to assign something different to that vals variable…
Step 3. Parse the Briefing Text
In the tutorial on creating a basic shell script, I've basically shown all the code you need to count up words of an arbitrary length from a text stream.
However, the raw HTML you pulled down from whitehouse.gov is not just ordinary prose. It's raw HTML, which is technically text, but contains a lot of boilerplate code that is not germane to the analysis (i.e. all the meta HTML code).
Since we've gone as far as we can with parsing HTML via regexes, I'll accept this messy hack: If you inspect the source of each briefing, you'll see that most of the text we want is between the tags <p> and </p>, e.g.
<p>In addition, today the President is also going to announce the American Technical Training Fund. This fund is designed to help high-potential, low-wage workers gain the skills they need to work in fields with significant numbers of middle-class jobs such as IT, energy, and advanced manufacturing.</p>
So write a grep filter that uses a regular expression to capture all the text between those tags, then perform the word count on that text.
Solution
Sit tight. This is a long explanation.
The setup
Assuming that the listings are in a subdirectory named:
./wh-listings
Setting this up:
mkdir ./wh-listings
mkdir ./wh-briefings # this is where files will be downloaded in
cd wh-listings
# get the index pages, i.e. 1.html, 2.html,...134.html
curl -o listings.zip http://stash.compciv.org.s3.amazonaws.com/wh/wh-press-briefings-listings-2015-01-07.zip
unzip listings.zip
# remove the listings zip
rm listings.zip
## move back up to the parent directory
cd ..
Note: I don't really care how you set up your data, though some of you had problems with downloading the new files into the same directory as your old ones…which would result in quite a few confusing things if you had to repeat the program…
The big picture
When possible, it's best to break up a project into steps, and to think what each step needs to do its job, and then what that step should deliver. This is called project planning and it is as much art as it is logic. There's not generally a right-or-wrong answer to this, just easier versus harder. Breaking things into smaller tasks makes debugging easier, but requires more upfront planning, and then some additional thinking on how to put the pieces together.
For this assignment, I think it's reasonably logical to think of it as three distinct steps.
The three steps
Before worrying how to tie these steps together, let's just focus on the code needed for each to do its job.
| Step | What it needs | What it delivers |
|---|---|---|
| The Grepper | HTML files in wh-listings/ | A list of relative URLs |
| The Curler | A list of relative URLs | HTML files in wh-briefings |
| The Counter | HTML files in wh-briefings | A list of top 10 words found |
Step 1: The Grepper
Assuming that all the listing pages are in wh-listings/ and are the result of downloading pages such as http://www.whitehouse.gov/briefing-room/press-briefings?page=120 into files named something like 120.html, this is how I would approach this step:
First, try one page at a time. No need to grep all 130+ pages at once:
cat ./wh-listings/42.html | grep '/the-press-office/'
Which produces ten lines that look like this:
<h3><a href="/the-press-office/2013/01/15/press-briefing-press-secretary-jay-carney-1152013">Press Briefing by Press Secretary Jay Carney, 1/15/2013</a></h3>
<h3><a href="/the-press-office/2013/01/09/press-briefing-press-secretary-jay-carney-192013">Press Briefing by Press Secretary Jay Carney, 1/9/2013</a></h3>
To make our life easier, we should just be looking at one line:
cat ./wh-listings/42.html| grep '/the-press-office/' | head -n 1
<h3><a href="/the-press-office/2013/01/15/press-briefing-press-secretary-jay-carney-1152013">Press Briefing by Press Secretary Jay Carney, 1/15/2013</a></h3>
So grep by default prints the entire line in which a match (in this case, of the term /the-press-office/) is found. We need a way to isolate just the URL, i.e. what's between quotation marks.
Grep and regex
This step was probably one of the hardest, if you didn't realize from the reading about grep that the -o option, which makes grep show only the match (as opposed to the line) needed to be paired with the option -E, and some knowledge of regular expressions. Either option alone would've been unhelpful.
Step 1 solution
Here's one possible solution, which uses the negated character class ([^]) and the one-or-more repetition operator (+) to basically say, I want all characters starting from /the-press-office/ that are not quotation marks:
cat ./wh-listings/42.html | grep -oE '/the-press-office/[^"]+' | head -n 1
To produce all 1,300+ briefing URLs, you simply need to pass a wildcard into cat and remove the head command:
cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+'
How do we pass all of these URLs into the next step? Let's worry about that later. For now, let's just worry about making one of those relative URLs work in the next step. We can assign it to a variable for easier reference:
some_url=/the-press-office/2011/10/03/press-briefing-press-secretary-jay-carney
Step 2: The Curler
We already know how to download URLs from the command-line; we use curl:
curl $some_url
Relative to absolute URLs
However, given the relative URL in $some_url, we will get this error:
curl: (3) <url> malformed
A brief aside on HTML terminology: when the URLs were scraped from the White House pages, they were in relative form:
/the-press-office/2011/10/03/press-briefing-press-secretary-jay-carney
The absolute form of this URL means appending the domain of the URL from which the relative URL was found, i.e. www.whitehouse.gov:
http://www.whitehouse.gov/the-press-office/2011/10/03/press-...(etc)
So to effectively download the relative URL stored in $some_url:
curl "http://www.whitehouse.gov$some_url"
For loops
From the previous assignment, we were introduced to the for-loop:
for num in $(seq 0 2); do
curl http://example.com -o $num.html
done
If you didn't understand it then (and if you didn't right away, then that's little fault of your own, it's a computer science concept that isn't instinctively obvious), this part may have seemed impossible or incomprehensible.
You had to understand that the for loop accepts a collection of things. In the previous assignment, it was the result of seq 0 134 – a list of numbers 0 to 134, which we wrapped up via command substitution as $(seq 0 134) and passed to the for loop:
for num in $(seq 0 134); do
curl http://www.whitehouse.gov/briefing-room/press-briefings?page=$num \
-o $num.html
done
For every number, from 0 to 134, the code within the do/done was repeated, and each time, the variable num took on one of the values of 0 to 134. The result was a download of pages 0 to 134, i.e. 135 separate briefings listings.
For this assignment, the concept was no different. We have to pass a collection of URLs into the for-loop. How do we get a collection of URLs? From the first step:
for some_url in $(cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+')
do
curl "http://www.whitehouse.gov$some_url"
done
We can use a variable to make things easier to read (though it makes no difference to the Bash interpreter):
urls=$(cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+')
for some_url in $urls; do
curl "http://www.whitehouse.gov$some_url"
done
Do things within the for-loop
At this point, we're almost done with Step 2. Except the curl command is just dumping data into standard output, i.e. our screen. We want to be able to save each page.
Again, consider the solution to the previous assignment:
main_url="http://www.whitehouse.gov/briefing-room/press-briefings?page="
for num in $(seq 0 134); do
curl "$main_url$num" -o $num.html
done
Everytime curl downloaded a page, it was saved into $num.html, i.e. 1.html, 20.html, 134.html. It was pretty easy to make a new filenamebased for every new number.
What happens when we try it in the for-loop of this assignment? Try it on just one URL, i.e. pretend we're inside the for-loop, just performing one iteration:
some_url=/the-press-office/2011/10/03/press-briefing-press-secretary-jay-carney
curl "http://www.whitehouse.gov$some_url" -o $some_url.html
We'll get an error that looks like this:
Warning: ...html: No such file or directory
curl: (23) Failed writing body (0 != 3396)
If you try to diagnose the error, you should come to the conclusion that the forward-slashes, /, that are part of the relative URL, are the source of the problem: we can't save the given filename because it expects the subdirectories /the-press-office/2011/10/03/ to exist.
We could create sub-directories for each individual file. But that seems like a lot of overhead. So let's think of this in the most low-brow way: if forward-slashes are the root of our problem, why not just get rid of them?
echo $some_url | tr '/' 'x'
# xthe-press-officex2011x10_03xpress-briefing-press-secretary-jay-carney
Does this seem too simplistic? For some bigger real-world software projects, maybe. But that's not what we need, we just need a directory of briefing HTML files that will be, in Step 3, catted together and grepped. So who cares what each file is named?
Step 2 solution
Here's a possible solution for Step 2, with the creation of a ./wh-briefings sub-directory to hold all 1,300+ of the downloaded files. Note that I've also omitted the .html file extension in the curl output: again, it makes no difference what the files are named, just that each of the 1,300+ files have a different name:
urls=$(cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+')
for some_url in $urls; do
fname=$(echo $some_url | tr '/' 'x')
curl -s "http://www.whitehouse.gov$some_url" -o ./wh-briefings/$fname
# I've silenced curl, so this echo let's me know how things are going
echo "Downloading $some_url into $fname"
done
Again, we don't worry about how to get this data to Step 3. It's enough that Step 2 has delivered what we planned: HTML files in wh-briefings
Step 3: The counter
This step simply expects files to be in ./wh-briefings; it then runs the commands and filters needed to:
- Concatenate them together into one text stream
- Match the text between
<p>and</p> - Use a regex to match and print only words of 7-letters or longer (this would effectively ignore all the
<p>tags matched in the previous grep) - Translate upper-case letters to lower-case letters, as
Presidentis considered different frompresident - Sort the words alphabetically so that
uniqwill work - Use
uniqand its-coption to print a count of each unique word - With the counts of each word in the left column, we sort again in reverse order (by number value) to get the list sorted by top counts
- Trim the list to the top 10 words
Step 3 solution
cat ./wh-briefings/* | \
grep -oE '<p>[^<]+' | \
grep -oE '[[:alpha:]]{7,}' | \
tr '[:upper:]' '[:lower:]' | \
sort | \
uniq -c | \
sort -rn | \
head -n 10
The answer? It varies, depending on when you initially scraped the White House site. My count is low because I gathered the listings earlier than most of you, i.e. there are new press briefings every day:
48637 president
8530 because
7196 american
7129 administration
6750 earnest
6523 question
6505 secretary
6272 security
6213 congress
5768 important
Alternative solution: all the content
Hopefully one side-lesson you've learned is that when dealing with HTML, grep is an imperfect tool. In fact, as it turns out, just filtering for text with <p> elements results in a massive undercount, as many briefings did not use those. I did mention the option of just grepping the entirety of HTML. Here's what that would look like (basically, one less grep) and the results:
cat ./wh-briefings/* | \
grep -oE '[[:alpha:]]{7,}' | \
tr '[:upper:]' '[:lower:]' | \
sort | \
uniq -c | \
sort -rn | \
head -n 10
101637 president
46317 content
45630 container
35506 whitehouse
34035 briefing
31539 administration
28185 siblings
28182 menuparent
24617 government
23550 section
Notice the prevalence of words that are, after closer inspection, are words in the HTML tags, which are generally not what we'd want for an assignment like this (i.e. counting words actually used in briefings). But since grepping in HTML is a generally pointless affair, I didn't judge based on your success in it, though it does set up the desire to learn HTML-specific parsing techniques:
All together
Even if you got the steps correct individually, it may not be evident how they all fit. Again, this is just logic applied at a larger scale, but mostly, it boils down to: just keep it simple.
Here's one possible combination (after the setup step has been done, and the listing pages are in ./wh-listings:
# Step 1
urls=$(cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+')
# Step 2 (assumes that `urls` variable has the relative URLs)
for some_url in $urls; do
fname=$(echo $some_url | tr '/' 'x')
curl -s "http://www.whitehouse.gov$some_url" -o ./wh-briefings/$fname
# I've silenced curl, so this echo let's me know how things are going
echo "Downloading $some_url into $fname"
done
# Step 3
cat ./wh-briefings/* | \
grep -oE '<p>[^<]+' | grep -oE '[[:alpha:]]{7,}' \
tr '[:upper:]' '[:lower:]' | \
sort | uniq -c | sort -rn | head -n 10
Some of you opted to save Step 1 into a text file, which is fine, though creates an intermediary file that isn't strictly necessary:
cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+' > urls.txt
# Step 2
urls=$(cat urls.txt)
# The rest of step 2 and step 3 are unchanged
# for some_url in $urls; do
And if you were feeling pretty adventurous, you could've put all this code into a shell script and backgrounded it, and then sent the answer directly to me via pipes as soon as all the pages were downloaded and analyzed:
# in a file named uber-wh-script.sh
# Step 1 (Same as previously)
urls=$(cat ./wh-listings/*.html | grep -oE '/the-press-office/[^"]+')
# Step 2 (same as previously, though removed the echo)
for some_url in $urls; do
fname=$(echo $some_url | tr '/' 'x')
curl -s "http://www.whitehouse.gov$some_url" -o ./wh-briefings/$fname
done
# Step 3 (same as previously, except for the pipe into mail)
cat ./wh-briefings/* | \
grep -oE '<p>[^<]+' | grep -oE '[[:alpha:]]{7,}' \
tr '[:upper:]' '[:lower:]' | \
sort | uniq -c | sort -rn | head -n 10 | \
mail dun@stanford.edu -s 'Top 10 WH Words via Grep'
And then, to background it on corn.stanford.edu
nohup krenew -t -- bash uber-wh-script.sh &
If you were frustrated with this assignment and felt lost, don't think about the relatively few lines of code it took to accomplish it, but the amount of planning, as well as knowledge of syntax and computer science concepts it takes to boil it down to a few lines of code. Nevermind the usual issues of dealing with scraping a live web-server.